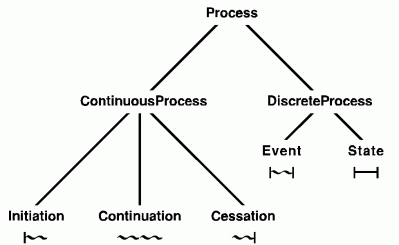
Figure 1: Types of Processes
Those who make causality one of the original uralt elements in the universe or one of the fundamental categories of thought — of whom you will find that I am not one — have one very awkward fact to explain away. It is that men's conceptions of a cause are in different stages of scientific culture entirely different and inconsistent. The great principle of causation which, we are told, it is absolutely impossible not to believe, has been one proposition at one period in history and an entirely disparate one at another is still a third one for the modern physicist. The only thing about it which has stood... is the name of it.Charles Sanders Peirce, Reasoning and the Logic of Things
The attempt to "analyze" causation seems to have reached an impasse; the proposals on hand seem so widely divergent that one wonders whether they are all analyses of one and the same concept.Jaegwon Kim, "Causation"
Abstract: In modern physics, the fundamental laws of nature are expressed in continuous systems of partial differential equations. Yet the words and concepts that people use in talking and reasoning about cause and effect are expressed in discrete terms that have no direct relationship to the theories of physics. As a result, there is a sharp break between the way that physicists characterize the world and the way that people usually talk about it. Yet all concepts and theories of causality, even those of modern physics, are only approximations to the still incompletely known principles of causation that govern the universe. For certain applications, the theories proposed by philosophers, physicists, and engineers may be useful approximations. Even "commonsense" theories that have never been formalized can be adequate guides for people to carry on their daily lives. To accommodate the full range of possible theories, whether formal or informal, scientific or rule of thumb, this paper proposes a continuum of law-governed processes, which bridge the gap between a totally random chaos and a totally predictable determinism. Various theories of causality can be interpreted according to the kinds of laws they assume and the tightness of the constraints they impose.
Contents:
This paper includes some material from my book Knowledge Representation and adds some new material that grew out of a series of e-mail exchanges. It also makes use of the ontology of processes presented in that book and summarized in a web page on processes. I acknowledge all the participants in the e-mail discussion for contributing ideas that I may have adopted, extended, modified, or reacted against.
No consensus about causality has emerged during the century from Peirce's remarks of 1898 to Kim's remarks of 1995. Yet people, animals, and even plants benefit from causal predictions about the universe, independent of any conscious thoughts they might have about causality. People plan their daily trips to work, school, or shopping; squirrels bury nuts for the winter; and plants turn their leaves upward and their roots downward. The success of these activities does not depend on a theory of physics that is accurate to seven decimal places, but it does imply that the universe is sufficiently regular that even a rough rule of thumb can be a useful guide for one's daily life. A general theory of causality must be able to accommodate the full range of approximations, ranging from sophisticated theories of physics to informal, often unconscious habits that enable an organism to survive and reproduce.
Three academic disciplines have addressed questions about causality: theoretical physics has the most detailed theories of causation with the most stringent criteria of accuracy and predictive power; philosophy has been proposing and analyzing notions of causality since the time of Aristotle; and artificial intelligence has been developing theories of causality intended to simulate intelligent behavior from the insect level to the human level and perhaps beyond. There is little hope of finding a single theory of causality that can satisfy the criteria of such widely divergent disciplines, each of which has contentious practitioners who seldom agree among themselves. The goal of this paper is more modest, but still ambitious: to propose a framework, which is compatible with modern physics, but which can be approximated at various levels of granularity for different purposes and applications.
In his lectures on cause and chance in physics, Max Born (1949) stated three assumptions that dominated physics until the twentieth century:
In physics, the best available approximations to the ultimate principles of causation are expressed as laws. In a discussion of causality, Peirce gave the following definition of law:
What is a law, then? It is a formula to which real events truly conform. By "conform," I mean that, taking the formula as a general principle, if experience shows that the formula applies to a given event, then the result will be confirmed by experience. (1904, p. 314)This definition is a realist view of the laws of nature, which is widely accepted by practicing scientists and engineers. Aronson, Harré, and Way (1994) presented a more recent, but essentially compatible view:
Laws are invariant relations between properties. We have argued that judgments of verisimilitude are based on similarity comparisons between the type of object referred to by a scientist and the actual type of the corresponding object in nature. The relative verisimilitude of laws can be thought of in the same way, namely as the degree to which the relationships between properties depicted in relevant theories resemble the actual relationships between properties in nature. (p. 142)In continuing their discussion, they remarked that the empirical methodology of science is not a rejection of "commonsense" practice, but a refinement of it:
It is the method of manipulation. It is so commonplace that we are hardly aware of its ubiquitous role in our lives and practice. Every time we turn on the shower and stand beneath it we are, in effect, using the unobservable gravitaional field to manipulate the water. The way that Stern and Gerlach manipulated magnetic fields to manipulate atomic nuclei in their famous apparatus is metaphysically much the same as our everyday strategy of standing under the shower. (p. 200)As Peirce would say, experience provides a pragmatic confirmation of the law of gravitation and its applicability to the event of taking a shower. But Peirce's view of law includes much more than the laws of logic and physics. In addition to the laws that make the shower work, he would include the habits and social conventions that cause people to take a shower. Various formulas "to which real events truly conform" can be observed, tested, and verified at every level from mechanical interactions to the conventions, habits, and instincts of living creatures.
The "impasse" that Kim observed in the divergent proposals about causation results from a fundamental divergence between practicing scientists and many, if not most twentieth-century philosophers. For scientists, the discovery of the laws of nature is the ultimate goal of their research; but for many philosophers, the concept of law is an embarrassing metaphysical notion. Yet Rudolf Carnap (1966), who had been one of the harshest critics of metaphysics, adopted the concept of law as the basis for analyzing the more elusive concept of causality:
From my point of view, it is more fruitful to replace the entire discussion of the meaning of causality by an investigation of the various kinds of laws that occur in science. When these laws are studied, it is a study of the kinds of causal connections that have been observed. The logical analysis of laws is certainly a clearer, more precise problem than the problem of what causality means.To unify the divergent views, both in science and in philosophy, this paper takes the notion of a law-governed process as fundamental. But to accommodate chance, either the fundamental uncertainty of quantum mechanics or the epistemological uncertainty that results from experimental error and limited observations, it does not assume that a law-governed process must be completely deterministic. Instead, there is a continuous range of possibilities between a totally random process and a totally deterministic process:
Processes can be described by their starting and stopping points and by the kinds of changes that take place in between. Figure 1 shows the category Process subdivided by the distinction of continuous change versus discrete change. In a continuous process, which is the normal kind of physical process, incremental changes take place continuously. In a discrete process, which is typical of computer programs or idealized approximations to physical processes, changes occur in discrete steps called events, which are interleaved with periods of inactivity called states. A continuous process with an explicit starting point is called an initiation; one with an ending point is a cessation; and one whose endpoints are not being considered is a continuation.
Figure 1: Types of Processes
Beneath each of the five categories at the leaves of Figure 1 is an icon that illustrates the kind of change: a vertical bar indicates an endpoint, a wavy horizontal line indicates change, and a straight horizontal line indicates no change. A discrete process is a sequence of states and events that may be symbolized by a chain of straight and wavy lines separated by vertical bars. A continuous process may be symbolized by a continuous wavy line with occasional vertical bars. Those bars do not indicate a break in the physical process, but a discontinuity in the way the process is classified or described. The weather, for example, varies by continuous gradations, but different time periods may be classified as hot or cold, cloudy or sunny.
Section 2 of this paper relates continuous processes to the laws of physics. In Section 3, discrete processes are defined as directed acyclic graphs (DAGs), which can approximate the continuous processes as a limit. Section 4 introduces procedures as specifications for classes of discrete processes, and shows how they can be expressed in the formalisms of Petri nets and linear logic. Section 5 shows how Petri nets or linear logic can be used to reason about discrete law-governed processes. To relate theories to one another and to the ultimate laws of nature, Section 6 introduces the lattice of all possible theories and the techniques for navigating it. In conclusion, Section 7 shows how various theories of causality can be interpreted in terms of the lattice.
The currently known laws of physics, which are the best available approximations to the ultimate principles of causation, are expressed in differential equations defined over a four-dimensional space-time continuum. Those equations relate functions, such the electric field E, the magnetic field H, and the quantum-mechanical field Ψ. A continuous process can be defined as a collection of such functions on a differentiable manifold M, which represents some region of space-time. Such manifolds can represent the warped universes of general relativity, but they can also be treated as locally flat: around every point, there is a neighborhood that can be mapped to a Euclidean space by a continuous, one-to-one mapping called a homeomorphism. Since a one-to-one mapping has a unique inverse, the four coordinates that identify points in the Euclidean space can also be used to identify points in the neighborhood.
2.1 Definition of continuous process: A continuous process P is a pair (F,M) consisting of a collection F of differentiable functions defined on a four-dimensional manifold M.
The mapping from each neighborhood into Euclidean 4-space determines a local coordinate system around every point of the manifold M. Axiom 2.2 introduces the option of joining overlapping neighborhoods and extending the coordinate system to the larger neighborhood. Any finite number of unions of neighborhoods is also a neighborhood, but a covering of the entire manifold may require a countably infinite number of neighborhoods. In the general case, the entire manifold might not have a globally unique coordinate system. A spherical universe, for example, has no one-to-one mapping into a flat Euclidean space.
2.2 Axiom of extensibility: For any continuous process P=(F,M), the manifold M can be covered by a countable union of neighborhoods. If U and V are two overlapping neighborhoods, then their union U∪V and their intersection U∩V are also neighborhoods with homeomorphisms into E4.
The local neighborhoods of the manifold M may be extended around, but not across singularities, such as black holes. If the manifold happens to represent Newton's conception of absolute space and time, the local mappings could be extended to a global isomorphism of M to Euclidean 4-space. Definition 2.1 and Axiom 2.2, however, are general enough to accommodate the geometries Einstein used for the special and general theories of relativity. They could even be generalized to more exotic conceptions, such as a multidimensional superstring theory.
Calling coordinate x4 the time coordinate does nothing to distinguish it from the three space-like coordinates. To distinguish time from space, Axiom 2.3 adds a constraint, which implies that time travel to the past is impossible. It is a safe assumption for any processes that have been observed within the solar system, but there is still some controversy about its universal applicability to remote regions of the universe (Yourgrau 1999).
2.3 Axiom against time loops: No path in which the time coordinate increases monotonically along the path can form a loop. Formally, if m: (a,b)→M is a continuous map, and for any two points x,y on the interval (a,b), x<y implies t(m(x))<t(m(y)), then m must be a one-to-one mapping.
Although Axiom 2.3 prohibits time loops,there is no prohibition against loops in the space-like coordinates. On the earth, for example, the coordinates of latitude and longitude are locally flat, but it is possible to have a loop in which the longitude increases monotonically: on a trip around the world, a point at longitude 360°+x can coincide with a point at x.
The fundamental laws of physics govern all processes from intergalactic motions to subatomic interactions. Derived laws, such as the equations of fluid mechanics, involve functions, such as temperature or fluid density, which are averaged over regions that may be small compared to M, but large compared to individual atoms and molecules. Other functions could be defined in terms of arbitrarily large configurations of space-time. The predicate isInObject(p,e), for example, might mean that the point p is inside object e. That predicate could be specialized to more detailed predicates like isInHuman(p,e) or isInChair(p,e), which would mean that p is inside a human being or a chair.
The laws of physics, both fundamental and derived, allow people to make predictions about the future. One of the fundamental laws, for example, requires any object with mass to travel slower than the speed of light c. Therefore, if an object is observed at point p and it still exists at an interval Δt later, it cannot be farther than cΔt from p. More specialized laws can tighten the constraints further. If a man is seen on foot, for example, and no other means of transportation is available, then four minutes later, it's highly unlikely that he would be more than a mile away. A constraint on a process is a relation among the functions of that process that limits their range of permissible values.
2.4 Definition of constraint: A constraint on a continuous process P=(F,M) is a predicate C: 2F×M→{true,false}. If S is any subset of functions in F and U is any open neighborhood of M for which C(S,p) is true for all p in U, then C is said to constrain the functions in S on the neighborhood U.
A constraint may be a general principle, such as the conservation of energy, or it could be a statement about the details of a specific problem. It could be a low-level statement about the energy in a particular region, or it could be high-level statement, such as There exists a cat on a mat. A constraint can have a causal effect by creating dependencies between the values of functions at different points: an energy increase at one point must cause an energy decrease somewhere else; a cat on a mat cannot change into a dog or move off the mat faster than the speed of light.
Some constraints, such as the principle of least action, involve global conditions that may relate the values of functions at some point to the values of functions in the past or in the future. A causal constraint must be stated in a form that explicitly accounts for limitations on the speed of information propagation. Such constraints limit the causal influences to a region called the light cone, which is illustrated in Figure 2. The arrow pointing to the right represents the time axis, which is measured by the time-like coordinate x4. The arrow pointing up represents any of the three spatial coordinates x1, x2, or x3.
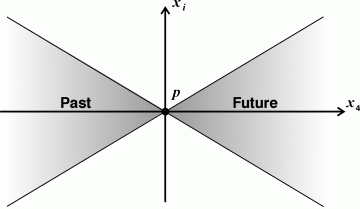
Figure 2. Cross section of the light cone with apex at point p
The light cone was introduced by Albert Einstein in the theory of relativity, which predicts that no information can propagate faster than the speed of light. In Figure 2, the values of functions at points that lie in the shaded area to the left of the point p can have a causal influence on the values at p. Similarly, the values at p can have a causal influence on the values in the shaded area to the right of p. The term light cone may be replaced by the more general term cone of causal influence, since anything outside the cone cannot influence or be influenced by anything that happens at p.
2.5 Definition of past and future: Let P=(F,M) be a continuous process, and p any point in M.
(y1−x1)2 + (y2−x2)2 + (y3−x3)2 ≤ c2(y4−x4)2The constant c is called the speed of information propagation. Its upper limit is the speed of light in a vacuum.
Although the light cone was first recognized as a fundamental concept in relativity, the general principle applies to any kind of reasoning about causality. If the speed of information propagation is c, the only events that can have a causal influence at a given point are those inside the past half of the cone determined by c. In fluid mechanics, the speed of sound is the normal maximum for information propagation. Therefore, a jet plane that is traveling faster than sound is outside the cone of causal influence for a molecule of air in its path. That molecule would not be influenced by the oncoming jet until it was hit by the leading edge of the plane or by its shockwave.
2.6 Definition of causal constraint: Let P=(F,M) be a continuous process, and C a constraint on P.
In a random process, the values of the functions in the past have no discernible relationship to their values in the future. A man might suddenly vanish and reappear in a distant galaxy as a duck. In a law-governed process, propositions called laws place constraints on the variability of the functions over time. In a deterministic process, the constraints are so tight that the laws can predict a unique value for every function at all points in the future in terms of their values at some points in the past.
2.7 Definition of law-governed process: A continuous process P=(F,M) may be classified according to the kinds of constraints that can be imposed on the functions in F.
The limiting cases of totally random or totally deterministic processes have never been observed. All observable processes are more or less law governed, and the primary question is not whether they are predictable, but whether the constraints can be tightened to limit the range of uncertainty. Quantum mechanics introduces uncertainty at the most fundamental level, but uncertainty can also arise from a lack of knowledge or the inability to observe the values of relevant functions.
Although it is not possible to travel backward in time, the present values of many physical functions can be computed either from past values or from future values. The laws of mechanics, for example, are reversible: from the current trajectory of a ballistic missile, it is possible to compute both its origin in the past and its target in the future. The laws of thermodynamics, however, are not reversible because they lose information by taking averages. If the temperature of a cup of water is 50°C, there is no way to determine whether it had been heated to that temperature, cooled to that temperature, or formed as a mixture of a half cup at 25°C with a half cup at 75°C. Since most activities at human scales are characterized by functions defined by averages or other methods that lose information, most processes of interest are not reversible. That principle is stated in Axiom 2.8.
2.8 Axiom of nonreversibility: If P=(F,M) is a law-governed process with a constraint C, then there are some functions in F whose values at some p in M are not constrained by the values of the functions in F at points in the future with respect to p.
The axioms and definitions presented so far have more geometry than physics built into them. They incorporate the following assumptions:
Although physical processes are continuous, discrete approximations are necessary for most methods of reasoning, measurement, and computation. The predicates for reasoning about processes are usually based on the discrete words and concepts that people use for talking about them. Empirical observations usually generate discrete values measured at points where the instruments are located. And in digital computers, the differential equations that relate the continuous functions are approximated by difference equations over a discrete grid of points. Figure 3 illustrates the kinds of grids that are used to approximate differential equations. It shows a point p at time t=0, whose values are computed in terms of neighboring points at time t=−1, whose values are computed in terms of other points at time t=−2. The resulting pattern of computation bears a strong resemblance to the cone of causal influence illustrated in Figure 2.

Figure 3. Discrete approximation to the cone of causal influence
The selection of points to be evaluated depends partly on the application and partly on the methods of reasoning or computation. For some computations, evenly spaced grids of points are the most efficient, but some techniques, called Monte Carlo methods, are based on randomly distributed points. For a robot that moves rigid objects, the most significant points are on the surfaces of the objects and at the ends of the robot's sensors and manipulators. Despite the differences in applications and methods of computation, all the patterns of causal influence resemble the cone in Figure 3. For any point p at a time t, the causal influences depend on the values of functions at some selected set of points at a previous time step. The values at those points, in turn, depend on a somewhat larger set of points at some earlier time step. The resulting cone of influence can be plotted as a graph of lines that represent the causal dependencies. Since the values at any point never depend on values from the future, the result is always a directed acyclic graph.
Directed graphs have been used for representing and reasoning about cause and effect in many systems of artificial intelligence. Chuck Rieger (1976) developed a version of causal networks, which he used for analyzing problem descriptions in English and translating them to a network that could support metalevel reasoning. Benjamin Kuipers (1984, 1994), who was strongly influenced by Rieger's approach, developed methods of qualitative reasoning, which serve as a bridge between the symbolic methods of AI and the differential equations of physics. Judea Pearl (1988, 1996, 2000) introduced belief networks, which are causal networks whose links are labeled with probabilities. The word belief is an important qualifier because all the representations used in AI represent somebody's best guess or belief about causal influences rather than the ultimate facts of causation. Definition 3.1 generalizes and formalizes those approaches in an abstract statement that is independent of any particular notation.
3.1 Definition of discrete process: A discrete process P is a directed, acyclic, bipartite graph (S,E,A), in which S is a set of nodes called states, E is a set of nodes called events, and A is a set of ordered pairs of nodes called arcs.
Since any model of discrete processes must accommodate acyclic causal links between discrete nodes, the most general possible models are DAGs with causal influences as the connecting arcs. The additional assumption of bipartite graphs with a disjoint set of state nodes and event nodes is a formal convenience that does not limit the generality. It would be possible to define a semantically equivalent theory with only state nodes, only event nodes, or nodes that could be either states or events. The primary reason for distinguishing two kinds of nodes is to simplify the discussion: conditions that may persist for some duration are defined at state nodes, and changes that occur between states are lumped into event nodes.
Another reason for distinguishing states and events is to simplify the mapping to natural languages. Most languages distinguish verb classes that represent events from other word classes, such as adjectives or verbs, that represent states. Verbs classify events in event types, such as raining, snowing, rising, falling, or eating. Associated with each event type are certain state types, some of which may be causes or preconditions of the event and some may be results or postconditions. An event of raining, for example, has a cloud as a precondition and wet ground as a postcondition. An event of sunrise has the absence of sunlight as a precondition and the presence of sunlight as a postcondition. An event of eating has the presence of food and an animal as preconditions and a decrease in the food and an increase in the weight of the animal as postconditions. Axiom 3.2 assumes that the state and event types may be organized in hierarchies according to their level of generalization or specialization.
3.2 Axiom of generalization hierarchy: There exists a partially ordered set T of monadic predicates called the generalization hierarchy of types.
The generalization hierarchy T includes all the state and event types, but it could also include any other types of entities that might be introduced into the ontology. Axiom 3.2 implies that the subhierarchy of state types has a top node called State, and the subhierarchy of event types has a top node called Event. The two subhierarchies are disjoint, but another ontology classifies both of them under a more general type called DiscreteProcess.
The type hierarchy consists of monadic predicates that characterize every instance of the type. The implications of those predicates are all the properties, relations, and axioms that must be true of the instances. Any instance may also have other features that are consistent with the type, but not implied by it. A general type, such as Animal, has fewer implications than a more specialized type, such as Mammal, Rodent, or Squirrel. As Aronson, Harré, and Way (1994) observed, "A model and its subject are, in general, related as instantiations of two subtypes under a common supertype. The shorter the 'distance' of each from their common node, the more similar their instantiations must be. Theories are tested for type adequacy by comparisons between their models and the reality those models represent."
Every event type has a fixed number of input state types called its preconditions and a fixed number of output state types called its postconditions. The list of preconditions and postconditions is called the signature of the event type. For any event e of type p, the preconditions of p must be true of the input states of e, and the postconditions of p must be true of the output states of e. A more specialized event type, such as selling, may have more preconditions and postconditions than a more general type, such as giving.
3.3 Axiom of event signatures: For every event type p, there exists exactly one pair ‹Pre,Post›, called the signature of p. Pre is an n-tuple of state types called the preconditions of p, and Post is an m-tuple of state types called postconditions of p. For any event e of type p, the following must be true:
For continuous processes, time was introduced as one of the four coordinates used to identify points in the four-dimensional continuum. For discrete processes, temporal notions, such as before and after, can be defined in terms of causal dependencies. To measure time numerically, some repeatable event type must be adopted as a standard. Traditionally, those event types were based on the the sun, moon, and stars, whose motions were tracked with sundials, astrolabes, and larger structures such as Stonehenge. Any other sufficiently regular event type could be used as a standard for measuring time. Galileo used his own heartbeats to time falling bodies. Clocks have been based on dripping water, sifting sand, swinging pendulums, and the vibrations of springs, tuning forks, crystals, and atoms. All those clocks are based on the assumption that some event type is repeatable at regular intervals. In Königsberg, however, the residents considered Immanuel Kant's daily walks to be more regular than their own clocks, which they reset when he passed by.
3.4 Axiom of clocks and time: A clock is a specification for a set C of discrete processes, each of which has at least one state type called TimeStep and at least one event type called Tick.
Axiom 3.4 makes causal influence the basis for clocks, which are the instruments for measuring time. Since every tick of a clock has one input and one output time step, a clock must be a nonbranching process whose states and events are linearly ordered. Therefore, a linearly ordered sequence of numbers can be assigned to those states and events; that sequence is called time. A clock might have other states and events that have causal influences on the ticks or time steps, but they are not used for the purpose of measuring time. In presenting his theory of relativity, Einstein (1905) noted that all measurements of time depend on an observation of simultaneous events:
If we wish to describe the motion of a material point, we give the values of its coordinates as functions of the time. Now we must bear carefully in mind that a mathematical description of this kind has no physical meaning unless we are quite clear as to what we understand by "time." We have to take into account that all our judgments in which time plays a part are always judgments of simultaneous events. If, for instance, I say, "That train arrives here at 7 o'clock," I mean somthing like this: "The pointing of the small hand of my watch to 7 and the arrival of the train are simultaneous events."
As Einstein noted, the time of an event is determined by comparing it to the simultaneous occurrence of some tick of a clock. Then the number assigned to that tick is assumed to be the "time" of the event. The timing diagram in Figure 4 compares the occurrences of the states and events of some process to the ticks of some clock. One state or event is said to be simultaneous with another if one is plotted directly above or below the other.

Figure 4. States and events of a process compared with the ticks of a clock
In Figure 4, straight horizontal lines represent states, and wavy lines represent events. Vertical lines mark the beginning and end of any state or event. The timing diagram for the clock, which is drawn at the bottom of Figure 4, is labeled with the times of every tenth tick, which are so short that the vertical lines that mark their beginning and end blur into a single bar. The timing diagram at the top of Figure 4 is labeled with letters that name the state and event types: a, c, d, e, i, j, and l are state types; and b, f, g, h, and k are event types. The event type b has the signature ‹‹a›,‹c,d,e››, and the event type k has the signature ‹‹i,j›,‹l››.
Figure 4 shows that different occurrences of the same state and event types may take different lengths of time according to the clock. Since that clock is the only standard for time, there is no independent evidence for determining whether the clock is irregular or the process above it is irregular. By comparing parallel threads of the concurrent process, however, it is possible to find evidence that the durations of some state and event types must vary when measured by any clock, no matter how regular or irregular. The first occurrence of state type d, for example, is shorter than the first occurrences of state types c and e; but the second occurrence of d is longer than the second occurrences of c and e. The truth of that observation is independent of any irregularity in the clock.
In a continuous process, any neighborhood of space-time can be subdivided into smaller neighborhoods, in which the values of functions change by arbitrarily small amounts — the usual epsilons and deltas of calculus. Since discrete nodes cannot be arbitrarily subdivided, the corresponding operation on a discrete process, called refinement, must be performed in discrete steps. There are two ways of refining a discrete process: either by adding more states, events, and arcs or by replacing one or more states or events by more detailed subprocesses. Those two methods of refinement are described in the next definition.
3.5 Definition of refinement: A discrete process P2=(S2,E2,A2) is said to be a refinement of a discrete process P1=(S1,E1,A1) either if P1 is a subgraph of P2 or if P2 can be derived by replacing some state or event node x of P1 by a discrete process P3=(S3,E3,A3). The replacement of x by P3 must observe the following constraints:
Although Section 3 introduces discrete processes as approximations to continuous processes, none of the formal definitions and assumptions from 3.1 to 3.5 make any reference to the continuous processes discussed in Section 2. Therefore, it is possible to create models for and reason about discrete processes without making explicit reference to the continuous ones. The continuous processes, however, provide links between the discrete approximations and the continuous physical systems. The definitions and assumptions from 3.6 to 3.9 support mappings from the discrete processes to the continuous. Such mappings are necessary to import observations and measurements from the physical systems into the discrete models and to export predicted values from the discrete models to points in the physical world.
A continuous process can be approximated by an infinite number of discrete processes. Every state of each discrete process corresponds to one of the points of the continuous process. The events of the discrete process represent computations: each event evaluates the functions of the continuous process at the points that correspond to its input states and uses the values to compute approximate values of the functions at the points that correspond to its output states. In Figure 3, the point p corresponds to the output state of an event that has five input states. To compute the values of the functions at p, the computation for that event uses the values at the five points that correspond to its five input states. Definition 3.6 introduces the notion of an embedding, which maps the states and events of a discrete process to neighborhoods of a continuous process.
3.6 Definition of embedding: An embedding of a discrete process P1=(S,E,A) in a continuous process P2=(F,M) is a mapping m: S∪E→M from the states and events of P1 to points in M, which satisfies the following conditions:
The neighborhood of any state or event has a coordinate system that determines a local time for points in that neighborhood. Since the neighborhoods overlap, there are no precisely determined starting times and ending times for the states and events. For the purpose of synchronizing a clock, however, it is possible to choose a starting time for an event e that lies between the time t(m(e)) and the maximum of all the times t(m(s)) for every input state s of e. The ending time of e can be chosen as a time between t(m(e)) and the minimum of all the times t(m(s)) for every output state s of e. If relativistic effects are negligible, the entire manifold M of the continuous process would have a coordinate system that would allow globally synchronized clocks. But the definitions are general enough to accommodate different clocks in different neighborhoods, which might not be synchronized. Discrepancies might arise because of relativistic effects, errors in measurement, or delays in message passing.
The main reason for embedding a discrete process in a continuous process is to map values of functions from one to the other. The mapping from the continuous to the discrete is often called observation or perception because it uses the measurements of physical processes as input data for creating discrete models. The inverse mapping from discrete to continuous is called prediction because it uses values computed for the discrete process to predict continuous values that have not yet been observed. In experimental practice, many different methods are used for doing the mappings. Definition 3.7 formalizes the notion of prediction as a proposition that is implied by the predicate of a state type. It includes numeric predictions that a function has a particular value and qualitative predictions, such as The flower is red or A cat is on a mat.
3.7 Definition of prediction: Let P1=(S,E,A) be a discrete process embedded in a continuous process P2=(F,M) by a mapping m: S∪E→M.
A qualitative prediction may be true or false, but a numeric prediction is almost always false. The predicted values cannot correspond exactly to the continuous physical values because of the limited accuracy of all measuring instruments and the limited storage capacity of even the largest digital computers. Yet a predicted value may be adequate for a particular application if the difference between the actual value and the predicted value is sufficiently small. That difference is called the error.
3.8 Definition of error: Let P1=(S,E,A) be a discrete process embedded in a continuous process P2=(F,M) by a mapping m: S∪E→M. If f is any function in F and p is any point in M, then the error in the value of f at p is a value w defined by the following conditions:
To accommodate the inevitable mismatch between the actual values and the predicted values, Definitions 3.7 and 3.8 are stated in terms of durations, which are neighborhoods that can be large enough to include the physical points of interest and the closest points that can be measured or computed. Ideally, each neighborhood, which should be insignificantly small, should contain exactly one predicted value for each physical function. Unfortunately, the ideal is seldom achieved. To provide some glimmer of hope, Axiom 3.9 says that for any discrete process that approximates a continuous process, there always exists a refinement that gives a better approximation. For an engineer, the goal is find one that is adequate to solve the problem at hand.
3.9 Axiom of approximation: If P1=(S1,E1,A1) is a discrete process embedded in a continuous process P2=(F,M), then there exists another discrete process P3=(S3,E3,A3), which is said to be a better approximation to P2 than P1:
By decreasing the size of the neighborhoods in the set C, it is possible to tighten the constraints on the distances between the simulated points and the points where measurements are available. The grids in Figure 3 illustrate a typical layout of simulated points. The actual points where measurements are taken might not be exactly aligned with the grid, and the sizes and shapes of the neighborhoods may need to be adjusted to accommodate the discrepancies. By assuming that states and events can be replaced by subprocesses with arbitrarily fine gradations, Axiom 3.9 allows any discrete process to be refined as much as necessary to approximate a continuous process to any desired degree of precision.
In summary, the fundamental laws that govern physical processes are stated in terms of a space-time continuum, but they can be approximated to any desired degree of accuracy by discrete processes represented by directed acyclic graphs. The time coordinate of the continuum corresponds to the set of all possible measurements by a clock, and the spatial coordinates correspond to the set of all possible measurements by a rigid ruler. Causality, in David Hume's words, is the cement of the universe that keeps these measurements consistent and repeatable. It ensures that the ticks of a clock are regular and that a rigid ruler will give reliable measurements even after it is moved. This model is general enough to accommodate the major theories of time, processes, and causality used in logic and artificial intelligence:
A causal structure of a set of variables V is a directed acyclic graph in which each node corresponds to a distinct element of V, and each link represents a direct functional relationship among the corresponding variables.For any causal structure, it is possible to define a discrete process P1 embedded in a continuous process P2. Then Pearl's set of variables V is some subset of all values v such that there exists a state s in P1, there exists a function f in P2, and v is the value of f at the point m(s):
V ∨ {v : (∃s in P1) (∃f in P2) v=f(m(s))}.Each state s of the discrete process corresponds to the set of variables in V that are evaluated at s. The type predicate that is true of a state s can be defined as the conjunction of all the equations of the form v=f(m(s)). Each event e of the discrete process corresponds to a bundle of links from the variables for the input states of e to the variables for the output states of e. With this mapping, the notion of causal influence in Definition 3.1 is consistent with Pearl's Definition 2.2.3:
A variable X is said to have a causal influence on a variable Y if a directed path from X to Y exists in every minimal causal structure consistent with the data.The mapping between the two theories allows Pearl's methods for analyzing, representing, and reasoning about causality to be restated in terms of the processes defined in this paper.
The type predicates that are true or false of some state or event correspond to McCarthy's fluents, which are true or false of the situation that intersects the corresponding state or event. To represent causal influences, McCarthy defined a function cause(p)(s), which he said "is intended to mean that the situation s will lead in the future to a situation that satisfies the fluent p." Each application of the cause function would correspond to some path of causal influence in a discrete process or in one of Pearl's causal structures. Murray Shanahan (1977) summarizes several different variations of the situation calculus that have been defined and implemented by AI researchers. The mapping described here can be used to translate any of them to DAGs of states and events.
(∀e:Event)(∀f:Fluent)(Initiates(e,f) ⊃ Holds(After(e,f))).The first axiom says that for every event e and fluent f, if e initiates f, then f is true (holds) for some duration after e happens. Initiation corresponds to an output arc of an event, and the fluent is its postcondition. The second axiom says that for every event e and fluent f, if e terminates f, then f holds before e happens. Termination corresponds to an input arc of an event, and the fluent is its precondition.(∀e:Event)(∀f:Fluent)(Terminates(e,f) ⊃ Holds(Before(e,f))).
Although the event calculus limits events to a single input arc and a single output arc, the fluents at the inputs and outputs could be conjunctions of multiple simpler fluents. If each conjunction is split into fluents that are true of separate states, the event calculus would correspond to directed acyclic graphs that are equivalent to Pearl's causal structures or the discrete processes of Definition 3.1. Shanahan (1997) surveyed several variations of the event calculus, each of which can be mapped to DAGs by a similar correspondence. Some of the variations use an explicit representation of time; they could be represented by discrete processs that include a clock and a predicate such as simul(e,t), which states that event e occurs simutaneously with tick t of the clock.
Antony Galton (1995) surveyed both metrical and topological representations for time and their application to reasoning and problem solving. Johan van Benthem (1995) surveyed formalisms for topological time and techniques for reasoning with them. Erik Sandewall (1994; Sandewall & Shoham 1995) developed a systematic classification of process types and presented a detailed analysis of topological approaches to representing and reasoning about them. The general conclusion from these surveys is that temporal representations by themselves, either metrical or topological, are insufficient to solve problems involving causality. The next two quotations express that conclusion:
Galton's conclusions are less negative, partly because his eclectic approach allows him to introduce different representations for different problems. His Swiss army knife also includes a cause operator.
The PSL activity occurrences correspond to processes, and the PSL activities correspond to process types. As defined in the PSL core, the specification of activity occurrences is general enough to accommodate continuous processes or discrete processes. The extensions for defining the situation calculus are limited to discrete processes with the same restrictions as McCarthy's version. The PSL core axioms for timepoints specify a version of metrical time that presupposes a single global clock (or a collection of precisely synchronized clocks) that can determine the starting and ending timepoints for all activity occurrences. Those axioms can be supported by assuming a privileged discrete process called a clock and a predicate simul(x,t) that can determine the simultaneous occurrence of any starting point or ending point x and some clock tick t.
This survey indicates that a representation of discrete processes as directed acyclic graphs of states and events linked by causal influences is general enough to accommodate the other versions as special cases. The two most successful approaches to reasoning about causality in discrete processes are isomorphic to this model: Judea Pearl's causal structures and Kowalski and Sergot's event calculus. After an exhaustive analysis and comparison, Shanahan (1997) concluded that the event calculus has better characteristics than the situation calculus:
Pearl used probabilities for reasoning about the graphs, and Shanahan used circumscription, but many other techniques are possible. Section 4 of this paper shows how Petri nets or linear logic can be used to define procedures for specifying process types. Section 5 illustrates techniques for reasoning about processes by analyzing the procedures that specify them.
A procedure is a specification for a family of discrete processes. An example is a computer program, which can be written as static information on a piece of paper or in computer storage. An activation of that program is a discrete process, which can be represented by the directed graphs described in Section 3. Since those processes are represented by graphs, it is convenient to represent procedures by graphs as well. Figure 5 shows three graph notations for representing procedures. On the left is a flow chart, which uses boxes to represent events that change some data and diamonds to represent decisions, which may change the direction of the process. In the center is a finite-state machine, which uses circles to represent states and arcs to show the transitions from one state to the next. On the right is a Petri net, which can be considered a merger of a flow chart and a finite-state machine. The circles of the Petri net, which are called places, correspond to the states of the finite-state machine; the bars, called transitions, correspond to the events of the flow chart.
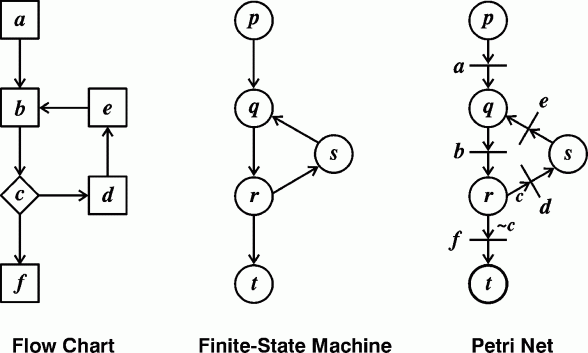
Figure 5. Three graphical notations for specifying procedures
Unlike processes, which consist of instances of states and events, procedures consist of state types and event types. Processes are represented by acyclic graphs because by Axiom 2.3 no path can ever loop back to an earlier point in time. Procedures, however, often contain loops. Those loops do not cycle back to an earlier time, but to another instance of the same type of state or event. In the diagrams of Figure 5, the state types are labeled p, q, r, s, and t; the events types are labeled a, b, d, e, and f. Any of the three notations in Figure 5 can be used to specify an infinite family of discrete processes. Following are the sequences of state and event types for the first three processes in the family:
p, a, q, b, r, f, t.The first sequence does not go through the loop, the second takes one pass through the loop, and the third takes two passes through the loop.p, a, q, b, r, d, s, e, q, b, r, f, t.
p, a, q, b, r, d, s, e, q, b, r, d, s, e, q, b, r, f, t.
Although flow charts and finite-state machines may contain branches and loops, they can only specify sequential processes, whose graphs are limited to nonbranching chains of states and events. The major strength of Petri nets is their ability to represent parallel or concurrent processes. The concurrent process shown in Figure 4 is a history of the execution of a Petri net. Other mechanisms and formalisms for specifying discrete concurrent processes can be treated as a variation or special case of a Petri net. The tokens that flow through a Petri net are generalizations of the markers that Ross Quillian (1966) and Scott Fahlman (1979) implemented in their versions of semantic networks. To illustrate the flow of tokens, Figure 6 shows a Petri net for a bus stop where three tokens represent people waiting and one token represents an arriving bus.
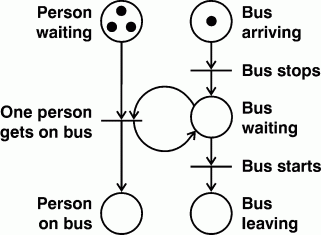
Figure 6. Petri net for a bus stop
At the upper left of Figure 6, each of the three dots is a token that represents one person waiting at the bus stop. The token at the upper right represents an arriving bus. The transition labeled Bus stops represents an event that fires by removing the token from the arriving place and putting a token in the waiting place. When the bus is waiting, the transition labeled One person gets on bus is enabled; it fires by first removing one token from the place for Person waiting and one token from the place for Bus waiting and then putting one token in the place for Person on bus and putting a token back in the place for Bus waiting. As long as the bus is waiting and there are more people waiting, that transition can keep firing. It stops firing when either there are no more people waiting or the Bus starts transition fires by removing the token for the waiting bus and putting a token in the place for Bus leaving. Figure 6 simulates a bus driver who stops whether or not anyone is waiting and leaves even when more people are still trying to get on. A Petri net for a more thoughtful bus driver would require more states and events for checking whether anyone is waiting.
The informal presentation of Petri nets as illustrated by Figure 6 has been formalized in many different variations since they were first introduced by Carl Adam Petri (1962). Definition 4.1 is based on the traditional terminology of places, transitions, and tokens together with some extensions that are compatible with the draft proposed standard for high-level Petri nets (ISO/IEC 1997). The terms for those extensions, however, have been modified to make them consistent with the definitions of discrete processes in Section 3 of this report.
4.1 Definition of Petri net: A Petri net N is a directed bipartite graph (P,T,A), where P is a set of nodes called places, T is a set of nodes called transitions, and A is a set of ordered pairs, called arcs, which are contained in P×T∪T×P.
Procedures can be specified in many different notations, but Petri nets are especially convenient because their graph structure has a direct mapping to discrete processes represented by directed acyclic graphs. The fundamental structure of processes and procedures, however, is independent of the details of the notation. As an example, linear logic is a notation that is formally equivalent to Petri nets although it has a very different appearance. The proof procedures of linear logic mimic the firing of Petri net transitions. Whenever an implication is used in a proof, the truth values of the antecedents are retracted, and the consequents are asserted. The movement of truth values through a proof in linear logic is isomorphic to the movement of tokens through a Petri net. Although some versions of linear logic are not decidable, Anne Troelstra (1992) showed that Petri nets are equivalent to a version of linear logic whose outcomes are decidable. Following is a translation of the Petri net of Figure 6 to a notation for linear logic:
BusStops: BusArriving ⇒ BusWaiting OnePersonGetsOnBus: PersonWaiting & BusWaiting ⇒ PersonOnBus & BusWaiting BusStarts: BusWaiting ⇒ BusLeaving InitialAssertions: PersonWaiting. PersonWaiting. PersonWaiting. BusArriving.Each transition of the Petri net becomes one implication in linear logic. The antecedent of the implication is the conjunction of the preconditions for the transition. The consequent is the conjunction of the postconditions. The loop in Figure 6, which shows that the bus continues to wait after a person gets on, can be represented in linear logic by reasserting the condition BusWaiting in the consequent of the rule that represents the event PersonGetsOnBus. The four tokens in the initial marking of the Petri net become four initial assertions in linear logic.
The notation of linear logic is similar to the production rules that are executed by forward-chaining inference engines in AI. When a production rule is executed, records or similar data structures are erased and asserted: one record is erased for every term on the left of the arrow, and a new record is asserted for every term on the right. The records correspond to the tokens in a Petri-net or the truth values in linear logic. The difference is in the level of formality: Petri nets and linear logic have been axiomatized and studied in depth, but systems of production rules have seldom been designed and analyzed with the same degree of rigor. The decidability of Petri nets or the equivalent version of linear logic means that the nets can be analyzed and theorems can be proved to characterize the kinds of processes that can be simulated.
Figure 7 shows a Petri net for a clock that conforms to Axiom 3.4. The transition named Tick is enabled by the token in the place labeled TimeStep. Every firing of that transition represents an event of type Tick, which immediately replaces the token in the TimeStep place and inserts another token into the place labeled Time. The numbers that the clock assigns to each state and event are indicated by the number of tokens that have accumulated in the Time place. Each tick is assigned the count of tokens in the Time place at the moment it finishes. Each time step may be assigned the count of tokens in the Time place plus some fraction, such as 0.5. For the clock in Figure 7, the most recent tick was assigned 4.0, and the current time step is assigned 4.5.
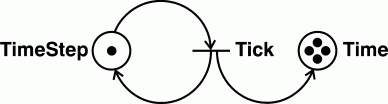
Figure 7. Petri net for a clock at time t=4
The Petri net in Figure 7 could be represented by a single rule in linear logic:
Tick: TimeStep ⇒ TimeStep & Time InitialAssertion: TimeStep.Each time this rule is used in a proof, the truth of the TimeStep condition is retracted. Then Time is asserted, and TimeStep is reasserted.
The clock in Figure 7 measures time by the number of tokens that have accumulated in the place called Time step, but the tokens might accumulate so fast that some additional mechanism may be needed to count them. Inside a mechanical clock, most of the gears are used to translate the high-speed ticks of a pendulum or vibrating spring to the much slower movement of the hour and minute hands. A digital clock would use a counter to translate a sequence of pulses to a number that counts how many pulses occurred.
In a quantified version of linear logic, another assertion could be added to initialize the clock: Time=0. Then the following rule could be used to count time steps:
(∀n)(TimeStep & Time=n ⇒ TimeStep & Time=n+1)In classical first-order logic, an implication of this form would be false because the conclusion could never be true when the antecedent is true. Linear logic, however, incorporates a kind of sequencing that is implicit in Petri nets and programming languages. It simulates the effect of an assignment statement such as N=N+1 in FORTRAN or N+=1 in C.
4.2 Definition of execution: If N is a Petri net (P,T,A), an execution of P is a sequence of functions, called markings, ‹m1,...,mn›.
(∀x in P)(∃!p)(p=type(x) ∧ (∀i in ‹1,...,n›)(∀d in mi(x))p(d)).
4.4 Theorem of Petri net histories: For every discrete process P, there exist one or more Petri nets whose history of execution includes P.
Sketch of proof: Let N be a Petri net that is isomorphic to P. For every state s of N that occurs in n>1 input arcs ‹s,ei› of N, insert an output arc ‹ei,s› for every i from 1 to n−1. For every state s of P that is not an output state of any event, insert one token in the initial marking of the corresponding state of N. Then the process P is one of the possible histories of N with that initial marking.
4.4 Definition of process type:
Steve Hanks and Drew McDermott (1987) posed a problem that has raised controversies about the role of logic in reasoning about time and causality. Named after their university, the Yale shooting problem concerns a person who is alive in a situation s0. In their version of the situation calculus, they replaced McCarthy's original cause operator with a function named result:
s1 = result(load,s0).
s2 = result(wait,s1) = result(wait, result(load,s0).
s3 = result(shoot,s2) = result(shoot, result(wait, result(load,s0))).

Figure 8. Finite-state machine for the Yale shooting problem
Hanks and McDermott found that the axioms of persistence in situation calculus cannot definitely predict the fate of the victim. With their representation, the state of a person being alive would normally persist, but the state of a gun being loaded would also persist. The situation calculus cannot determine whether the gun switches state from loaded to unloaded or the victim switches state from alive to dead. The length of time spent waiting between situation s1 and s2, for example, is not specified. If the waiting time had been a minute, the gun would be likely to remain loaded. But if the time had been a year, it's more likely that someone would have unloaded it. The person or persons who carried the gun, loaded it, pulled the trigger, or perhaps unloaded it are not mentioned, and their motives are unknown. The type of weapon, the distance between the assassin and the victim, the victim's movements, and the assassin's shooting skills are unknown. Without further information, no system of logic by itself can determine exactly what would happen.
As someone who has long worked on logic-based approaches to AI, McDermott had hoped that logic alone would be able to give a unique answer to the Yale shooting problem and other similar, but more practical problems. He reluctantly concluded that the versions of nonmonotonic logic used for reasoning about time cannot by themselves solve such problems:
The whole point behind the development of nonmonotonic formal systems for reasoning about time has been to augment our logical machinery so that it reflects in a natural way the "inertia of the world." All of this effort is wasted if one is trying merely to express constraints on the physics of the world: we can solve the problem once and for all by saying "once a fact becomes true it stays true until the occurrence of some event causes it to become false."... Many researchers, however, would not be satisfied with using logic only as a notation for expressing ontological theories.McDermott's method of solving the problem "once and for all" is a paraphrase of Leibniz's principle of sufficient reason. But as Leibniz observed, every entity in the universe has some influence on every other entity. Only an omniscient being such as God could account for the potentially infinite number of events that might cause a change. To determine which of those events are significant, finite reasoners — human or computer — must use background knowledge about physics to select the most likely causes and effects.
For the Yale shooting problem, Figure 9 takes advantage of the greater expressive power of Petri nets to show causal links between states and events that involve different participants. Following are the mappings from Petri nets to a distributed version of the situation calculus:
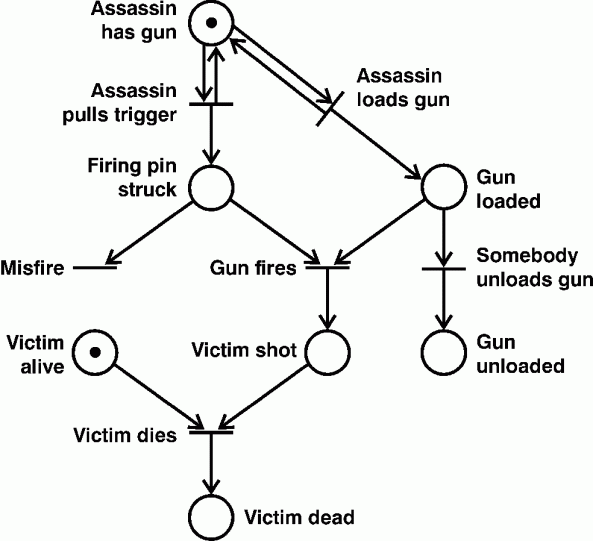
Figure 9. Petri net for the Yale shooting problem
Questions about future situations can be answered either by executing the Petri net interpretively or by proving theorems about which states are reachable. To determine what happens to the victim, trace the flow of tokens through Figure 9:
Following is the translation of the Petri net in Figure 9 to linear logic.
AssassinLoadsGun: AssassinHasGun ⇒ GunLoaded & AssassinHasGun AssassinPullsTrigger: AssassinHasGun ⇒ FiringPinStruck & AssassinHasGun SomebodyUnloadsGun: GunLoaded ⇒ GunUnloaded Misfire: FiringPinStruck ⇒ GunFires: FiringPinStruck & GunLoaded ⇒ VictimShot VictimDies: VictimAlive & VictimShot ⇒ VictimDead InitialAssertions: AssassinHasGun. VictimAlive.
To resolve the indeterminism that occurs at disjunctive nodes, Pearl would compute or estimate the probabilities of each of the options. When one option is much more likely than the other, he would derive a qualitative solution by assigning a small value ε to the unlikely option and the complementary value (1−ε) to the more likely option. For the network shown in Figure 9, there are three disjunctive nodes, each of which has one likely path and one unlikely path.
For a variety of problems in temporal reasoning, Peter Grünwald (1997) compared the solutions obtained with Pearl's belief networks to other proposed methods. For each of them, he showed that Pearl's approach was equivalent to, more general than, or intuitively more convincing than the others.
Although the world is bigger than any human can comprehend or any computer can compute, the set of all possible theories and models is even bigger. The entire universe contains a finite number of atoms, but the number of all possible theories is countably infinite, and the number of possible models of those theories is uncountably infinite. The ultimate task of science is to search that vast infinity in the hope of finding a theory that gives the best answers to all possible questions. Yet that search may be in vain. Perhaps no single theory is best for all questions; even if one theory happened to be the best, there is no assurance that it would ever be found; and even if somebody found it, there might be no way to prove that it is the best.
Engineers have a more modest goal. Instead of searching for the best possible theory for all problems, they are satisfied with a theory that is good enough for the specific problem at hand. When they are assigned a new problem, they look for a new theory that can solve it to an acceptable approximation within the constraints of available tools, budgets, and deadlines. Although no one has ever found a theory that can solve all problems, people everywhere have been successful in finding more or less adequate theories that can deal with the routine problems of daily life. As science progresses, the engineering techniques advance with it, but the engineers do not have to wait for a perfect theory before they can do their work.
 The set of all possible theories resembles the
Library of Babel
envisioned by the poet, storyteller, and librarian Jorge Luis Borges
(1941). His imaginary library consists of an infinite array of hexagonal
rooms with shelves of books containing everything that is known
or knowable. Unfortunately, the true books are scattered among
infinitely many readable but false books, which themselves are
an insignificant fraction of the unreadable books of random gibberish.
In the story by Borges, the library has no catalog, no discernable
organization, and no method for distinguishing the true, the false,
and the gibberish. In a prescient anticipation of the World Wide Web,
Borges described people who spend their lives aimlessly searching
through the rooms with the hope of finding some hidden secrets.
But no matter how much truth lies buried in such a collection,
it is useless without a method of organizing, evaluating, indexing,
and finding the books and the theories contained in them.
The set of all possible theories resembles the
Library of Babel
envisioned by the poet, storyteller, and librarian Jorge Luis Borges
(1941). His imaginary library consists of an infinite array of hexagonal
rooms with shelves of books containing everything that is known
or knowable. Unfortunately, the true books are scattered among
infinitely many readable but false books, which themselves are
an insignificant fraction of the unreadable books of random gibberish.
In the story by Borges, the library has no catalog, no discernable
organization, and no method for distinguishing the true, the false,
and the gibberish. In a prescient anticipation of the World Wide Web,
Borges described people who spend their lives aimlessly searching
through the rooms with the hope of finding some hidden secrets.
But no matter how much truth lies buried in such a collection,
it is useless without a method of organizing, evaluating, indexing,
and finding the books and the theories contained in them.
The first step toward making the theories accessible is to organize them in a systematic way. Figure 10 shows a few theories organized in a partial ordering called a generalization hierarchy. Each theory is a generalization of the ones below it and a specialization of the ones above it. The top theory contains all tautologies — all the logically true propositions like p⊃p that are provable from the empty set. Each theory below Tautologies is derived from the ones above it by adding new axioms; its theorems include all the theorems inherited from above plus all the new ones that can be proved from the new axioms or from their combination with the inherited axioms. Adding more axioms makes a theory larger, in the sense that it contains more propositions. But the larger theory is also more specialized, since it applies to a smaller range of possible models. This principle, which was first observed by Aristotle, is known as the inverse relationship between intension and extension: as the meaning or intension grows larger in terms of the number of axioms or defining conditions, the extension grows smaller in terms of the number of possible instances. As an example, more conditions are needed to define the type Dog than the type Animal; therefore, there are fewer instances of dogs in the world than there are animals.

Figure 10. A generalization hierarchy of theories
Just below Tautologies are four theories named Antisymmetry, Transitivity, Reflexivity, and Symmetry. Each of them includes all tautologies; in addition, each one has a single new axiom. The theory named Equivalence has three axioms, which it inherits from Transitivity, Reflexivity, and Symmetry. The = symbol represents a typical operator that satisfies these axioms:
PartialOrdering, which is the theory of the ≤ operator, inherits the axiom for Antisymmetry instead of Symmetry:
The traditional mathematical theories illustrated in Figure 10 are a small part of the infinitely many theories that can be used to describe any subject that can be defined precisely in any language, natural or artificial. When extended to all possible theories, the complete hierarchy is sufficient to formalize all the computer programs that have been written or ever will be written by humans, robots, compilers, and AI systems. Besides the elegant theories that mathematicians prefer to study, the hierarchy contains truly "ugly" theories for the poorly designed and undebugged programs that even their authors would disown. It contains theories for the high-powered formalisms of logicians like Richard Montague and the scruffy programs written by all the hackers of the world.
An infinite hierarchy without an index or catalog might contain all the theories that anyone would ever want or need, but no one would be able to find them. To organize the hierarchy of theories, the logician Adolf Lindenbaum showed that Boolean operators applied to the axioms would make it into a lattice:
p ≡ p1 ∧ ... ∧ pn.The axiom p is equivalent to the original list, since the standard rules of inference allow conjunctions to be taken apart or put together.

Figure 11. Navigating the lattice of theories
To illustrate the moves through the lattice, suppose that theory A is Newton's theory of gravitation applied to the earth revolving around the sun and that F is Niels Bohr's theory about an electron revolving around the nucleus of a hydrogen atom. The path from A to F is a step-by-step transformation of the old theory to the new one. The revision step from A to C replaces the gravitational attraction between the earth and the sun with the electrical attraction between the electron and the proton. That step can be carried out in two intermediate steps:
By repeated contraction, expansion, and analogy, any theory or collection of beliefs can be converted into any other. Multiple contractions would reduce a theory to the empty or universal theory T at the top of the lattice that contains only the tautologies that are true of everything. Multiple expansions would lead to the inconsistent or absurd theory ⊥ at the bottom of the lattice, which contains all axioms and is true of nothing. Each step through the lattice of theories is simple in itself, but the infinity of possible steps makes it difficult for both people and computers to find the best theory for a particular problem. Newton became famous for finding the axioms that explain the solar system, and Bohr won the Nobel Prize for revising them to explain the atom.
The problems of knowledge soup result from the difficulty of matching abstract theories to the physical world. The techniques of fuzziness, probability, defaults, revisions, and relevance are different ways of measuring, evaluating, or accommodating the inevitable mismatch. Each technique is a metalevel approach to the task of finding or constructing a theory and determining how well it approximates reality. To bridge the gap between theories and the world, Figure 12 shows models as Janus-like structures, with an engineering side facing the world and an abstract side facing the theories.
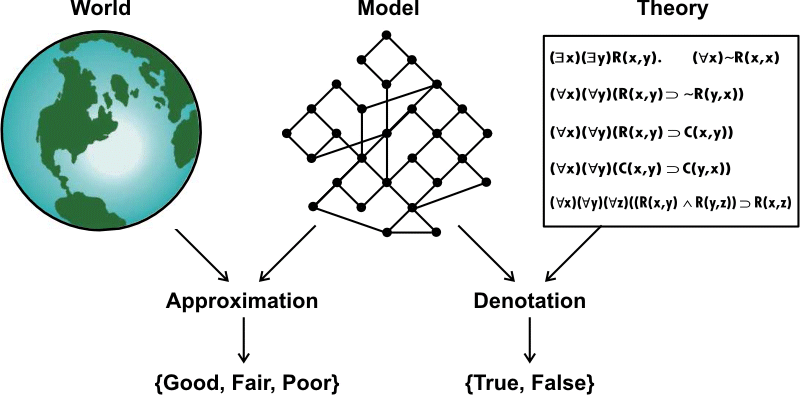
Figure 12. Relating a theory to the world
On the left is a picture of the physical world, which contains more detail and complexity than any humanly conceivable model or theory can represent. In the middle is a mathematical model that represents a domain of individuals D and a set of relations R over D. On the right of Figure 12 are the axioms of a theory that describes the world in terms of the individuals and relations in the model.
If the world had a unique decomposition into discrete objects and relations, the world itself would be a universal model, of which all accurate models would be subsets. But as the examples in this book have shown, the selection of a domain and its decomposition into objects depends on the intentions of some agent and the limitations of the agent's measuring instruments. Even the best models are approximations to a limited aspect of the world for a specific purpose. Engineers express that point in a pithy slogan: All models are wrong, but some are useful.
Mackie (1974): INUS condition -- Insufficient but Necessary part of an Unnecessary but Sufficient causal package. Most of the time, we do not know the full sufficient condition of which the INUS condition is a part.
Aronson, Jerrold L. (1984) A Realist Philosophy of Science, St. Martin's Press, New York.
Aronson, Jerrold L., Rom Harré, and Eileen C. Way (1994) Realism Rescued: How Scientific Progress is Possible, Duckworth Publishers, London.
Borges, Jorge Luis (1941) "La Biblioteca de Babel" translated as "The library of Babel" in Ficciones, Grove Press, New York.
Born, Max (1949) Natural Philosophy of Cause and Chance, Dover Publications, New York.
Brown, Frank M., ed. (1987) The Frame Problem in Artificial Intelligence, Morgan Kaufmann Publishers, San Mateo, CA.
Carnap, Rudolf (1954) Einführung in die symbolische Logik, translated by W. H. Meyer & J. Wilkinson as Introduction to Symbolic Logic and its Applications, Dover Publications, New York.
Carnap, Rudolf (1966) An Introduction to the Philosophy of Science, edited by Martin Gardner, Dover Publications, New York.
Einstein, Albert (1905) "Zur Elektrodynamik bewegter Körper," translated as "On the electrodynamics of moving bodies," in A. Einstein, H. A. Lorentz, H. Weyl, & H. Minkowski, The Principle of Relativity, Dover Publications, New York.
Fikes, Richard E., & Nils J. Nilsson (1971) "STRIPS: A new approach to the application of theorem proving to problem solving," Artificial Intelligence 2, 189-208.
Gabbay, Dov M., C. J. Hogger, & J. A. Robinson (1995) Handbook of Logic in Artificial Intelligence and Logic Programming, Vol. 4, Epistemic and Temporal Reasoning, Clarendon Press, Oxford.
Galton, Antony (1995) "Time and change for AI," in Gabbay et al. (1995) pp. 175-240.
Gopnik, Alison, Clark Glymour, & David Sobel (1999) "Causal maps and Bayes nets: A cognitive and computational account of theory formation," presented at the International Congress on Logic, Methodology and Philosophy of Science, Krakow. Available at http://www-psych.stanford.edu/~jbt/224/Gopnik_1.html
Grünwald, Peter (1997) "Causation and nonmonotonic temporal reasoning," in G. Brewka et al., KI-97: Advances in Artificial Intelligence, LNAI 1303, Springer-Verlag, Berlin, pp. 159-170. Extended presentation available in Technical Report INS-R9701, ftp://ftp.cwi.nl/pub/pdg/R9701.ps.Z.
Haack, Susan (1992) "'Extreme scholastic realism': its relevance for philsophy of science today," Transactions of the Charles S. Peirce Society 28, 19-50.
Hanks, Steven, & Drew McDermott (1987) "Nonmonotonic logic and temporal projection," Artificial Intelligence 33, 379-412.
Hulswit, Menno (1998) A Semeiotic Account of Causation: The 'Cement of the Universe' from a Peircean Perspective, PhD dissertation, Katholieke Universiteit Nijmegen.
ISO/IEC (1997) High-Level Petri Nets &mdash. Concepts, Definitions, and Graphical Notation, Committee Draft ISO/IEC 15909, version 3.4.
Kim, Jaegwon (1995) "Causation," in R. Audi, ed., The Cambridge Dictionary of Philosophy, Cambridge University Press, Cambridge. Second edition, 1999, pp. 125-127.
Kowalski, R. A., & M. J. Sergot (1986) "A logic-based calculus of events," New Generation Computing 4, pp. 67-95.
Mackie, John L. (1974) The Cement of the Universe: A Study of Causation, Clarendon Press, Oxford, second edition 1980.
Manna, Zohar, & Amir Pnueli (1992) The Temporal Logic of Reactive and Concurrent Systems, Springer-Verlag, New York.
McCarthy, John (1963) :q.Situations, actions, and causal laws,:eq. reprinted in M. Minsky, ed., Semantic Information Processing, MIT Press, Cambridge, MA, pp. 410-418.
McCarthy, John, & Patrick Hayes (1969) :q.Some philosophical problems from the standpoint of artificial intelligence,:eq. in B. Meltzer & D. Michie, eds., Machine Learning 4, Edinburgh University Press.
McDermott, Drew V. (1987) "AI, logic, and the frame problem," in Brown (1987) pp. 105-118.
Pearl, Judea (1986) "Fusion, propagation, and structuring in belief networks," Artificial Intelligence 29, 241-288. Reprinted in Shafer & Pearl (1990).
Pearl, Judea (1988) Probabilistic Reasoning in Intelligent Systems, Morgan Kaufmann Publishers, San Mateo, CA.
Pearl, Judea (1988) "Embracing causality in default reasoning," Artificial Intelligence 35, 259-271. Reprinted in Shafer & Pearl (1990).
Pearl, Judea (1996) "Causation, explanation, and nonmonotonic temporal reasoning," Proc TARK-VI, Morgan Kaufmann, San Mateo, CA, pp. 51-73.
Pearl, Judea (1999) "Reasoning with cause and effect," Proceedings IJCAI99.
Pearl, Judea (2000) Causality: Models, Reasoning, and Inference, Cambridge University Press.
Petri, Carl Adam (1962) Kommunikation mit Automaten, Ph.D. dissertation, University of Bonn. English translation in technical report RADC-TR-65-377, Griffiss Air Force Base, 1966.
Peirce, Charles Sanders (1898) Reasoning and the Logic of Things, The Cambridge Conferences Lectures of 1898, ed. by K. L. Ketner, Harvard University Press, Cambridge, MA, 1992.
Peirce, Charles Sanders (1904) "New Elements," in Peirce (EP) 2.300-324.
Peirce, Charles Sanders (CP) Collected Papers of C. S. Peirce, ed. by C. Hartshorne, P. Weiss, & A. Burks, 8 vols., Harvard University Press, Cambridge, MA, 1931-1958.
Peirce, Charles Sanders (EP) The Essential Peirce, ed. by N. Houser, C. Kloesel, and members of the Peirce Edition Project, 2 vols., Indiana University Press, Bloomington, 1991-1998.
Peirce, Charles Sanders (W) Writings of Charles S. Peirce, vols. 1-5, Indiana University Press, Bloomington, 1982-1993.
Sandewall, Erik (1994) Features and Fluents, Clarendon Press, Oxford.
Sandewall, Erik, & Yoav Shoham (1995) "Nonmonotonic temporal reasoning," in Gabbay et al. (1995) pp. 439-498.
Schlenoff, Craig, Michael Gruninger, Florence Tissot, John Valois, Josh Lubell, & Jintae Lee (1999) The Process Specification Language (PSL) Overview and Version 1.0 Specification, NIST Internal Report (NISTIR) 6459, http://www.mel.nist.gov/psl/pubs/PSL1.0/paper.doc
Shanahan, Murray (1997) Solving the Frame Problem, MIT Press, Cambridge, MA.
Sosa, Ernest, & Michael Tooley, eds. (1993) Causation, Oxford University Press, Oxford.
Sowa, John F. (2000) Knowledge Representation: Logical, Philosophical, and Computational Foundations, Brooks/Cole, Pacific Grove, CA.
van Bentham, Johan (1983) The Logic of Time, Reidel, Dordrecht, second edition 1991.
van Bentham, Johan (1995) "Temporal logic," in Gabbay et al. (1995) pp. 241-350.
Yourgrau, Palle (1999) Gödel Meets Einstein: Time Travel in the Gödel Universe, Open Court, Chicago.
Copyright ©2000 by John F. Sowa.
Last Modified: