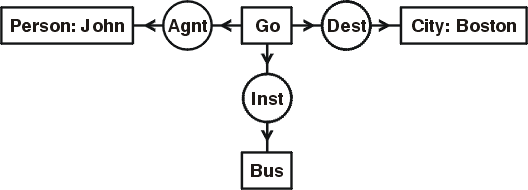
Figure 1: A conceptual graph in the display form
Abstract. People communicate with each other in sentences that incorporate two kinds of information: propositions about some subject, and metalevel speech acts that specify how the propositional information is used — as an assertion, a command, a question, or a promise. By means of speech acts, a group of people who have different areas of expertise can cooperate and dynamically reconfigure their social interactions to perform tasks and solve problems that would be difficult or impossible for any single individual. This paper proposes a framework for intelligent systems that consist of a variety of specialized components together with logic-based languages that can express propositions and speech acts about those propositions. The result is a system with a dynamically changing architecture that can be reconfigured in various ways: by a human knowledge engineer who specifies a script of speech acts that determine how the components interact; by a planning component that generates the speech acts to redirect the other components; or by a committee of components, which might include human assistants, whose speech acts serve to redirect one another. The components communicate by sending messages to a Linda-like blackboard, in which components accept messages that are either directed to them or that they consider themselves competent to handle.
Published in a Special Issue on Artificial Intelligence of the IBM Systems Journal, vol. 41, no.3, pp. 331-349, 2002.
In the years since its founding conference in 1956, the field of artificial intelligence has generated an impressive collection of valuable components, but no comparably successful architecture for assembling them into intelligent systems. As examples, the following list illustrates the range of AI components that were designed and implemented in the 1950s and '60s:
parsers, theorem provers, inference engines, search engines, learning programs, classification tools, statistical tools, neural networks, pattern matchers, problem solvers, planning systems, game-playing programs, question-answering systems, dialog managers, machine-translation systems, knowledge acquisition tools, modeling tools, and robot guidance systems.Over the past 40 years, the performance, reliability, and generality of these components have been vastly improved. Their theoretical foundations are much better understood, and they have found their way into applications that are no longer considered part of AI. Yet despite attempts to integrate the components into general-purpose intelligent systems, the results are disappointing: the commercially successful systems are limited to special-purpose applications, and the more general systems have not progressed beyond the stage of clever demos. Nothing remotely resembling the HAL computer in the movie 2001 exists today, and there are no credible designs for building one soon.
The lack of progress in building general-purpose intelligent systems could be explained by several different hypotheses:
The idea of a flexible modular framework (FMF) is not new. It is, in fact, the underlying philosophy of the Unix operating system and its descendants. That philosophy is characterized by four design principles:
The LISP language, which was the primary language of AI since the late 1950s, pioneered techniques that entered the mainstream of commercial computing when they were adopted by other languages ranging from PL/I to Java. For AI systems, LISP served as both an implementation language and a glue language for AI components and complete systems. Unlike the Unix character strings, the basic data structures of LISP consist of tree-like lists, which can be supplemented with cross links to form arbitrary graphs. During the 1970s and '80s, the trees and graphs of LISP proved to be rich enough to support the operating systems of the LISP machines with their stunning graphics. Those graphics techniques, which were invented at Xerox PARC, have been copied in all modern GUIs, including those of the Macintosh and Windows.
Although LISP was, and still is, a highly advanced programming language, it is not by itself a knowledge representation language. The Prolog language is a step closer to a KR language. It supports the same kinds of data structures as LISP, but it has a built-in inference engine for the Horn-clause subset of logic, which can be used to express the rules of an expert system or the grammars of natural languages. For many applications, Prolog has been used as a KR language, either directly or with some syntactic sugar to make its notation more palatable. Yet Prolog still has limitations that make it unsuitable as the glue language for intelligent systems: procedural dependencies, a nonstandard treatment of negation, and the limited expressive power of Horn-clause logic. Like LISP, Prolog is better suited to implementing the components of intelligent systems rather than representing the knowledge they process.
The most promising candidate for a glue language is Elephant 2000, which McCarthy (1989) proposed as a design goal for the AI languages of the new millennium. Sentences in the Elephant language include "requests, questions, offers, acceptances of offers, permissions as well as answers to questions and other assertions of fact. Its outputs also include promises and statements of commitment analogous to promises." As an inspiration for Elephant, McCarthy cited the speech acts of natural languages (Austin 1962; Searle 1969), but he believed that Elephant sentences should be written in a formally defined version of logic, rather than the much more informal natural languages. Unix only supports one kind of speech act: a command that invokes some program. The Unix scripting languages add loops and conditionals, which determine the sequence of commands to execute. Prolog supports two kinds of speech acts: assertions for stating facts and goals for issuing commands or asking questions. Besides those special cases, Elephant provides a framework that can support the full range of illocutionary and perlocutionary speech acts.
Although the glue language for intelligent systems should be at a higher level than the scripting languages of Unix, the four design principles of the Unix philosophy can serve as guidelines. Following are AI generalizations of the four principles:
This paper shows how a framework based on these four principles can support a family of architectures that can easily be tailored for different kinds of applications. Section 2 discusses three logically equivalent notations for an Elephant-like glue language: controlled natural language for the human interface; conceptual graphs for components that use graph-based algorithms; and KIF for components that use other notations for logic. Section 3 surveys the use of CNLs as a front end to AI systems. Section 4 shows how graph algorithms can simplify or clarify the techniques for searching, querying, and theorem proving. Section 5 discusses techniques for handling the computational complexities in different applications of logic. Finally, Section 6 discusses the kinds of components needed for a flexible modular framework and how a glue language communicating through a blackboard can be used to combine them, relate them, and drive them.
McCarthy's Elephant language requires a highly expressive version of logic, but he did not propose any particular notation for it. Although various notations — graphical, linear, or NL-like — can express equivalent semantic information, the choice of notation can have a major influence on both the human interfaces and the kinds of algorithms used in the computations. This section illustrates three notations for logic: conceptual graphs, KIF, and controlled natural languages. All three of them can express exactly the same semantics in logically equivalent ways, but they have complementary strengths and weaknesses that make them better suited to different kinds of tasks. Any or all of them could be used in messages passed through a Linda-like blackboard.
For his syllogisms, the first version of formal logic, Aristotle defined a highly stylized form of Greek, which became the world's first controlled natural language. During the middle ages, Aristotle's sentence patterns were translated to controlled Arabic and controlled Latin, and they became the major form of logic until the 20th century. The following table lists the names of the four types of propositions used in syllogisms and the corresponding sentence patterns that express them.
| Type | Name | Pattern |
|---|---|---|
| A | Universal affirmative | Every A is B. |
| I | Particular affirmative | Some A is B. |
| E | Universal negative | No A is B. |
| O | Particular negative | Some A is not B. |
With letters such as A and B in the sentence patterns, Aristotle introduced the first known use of variables in history. Each letter represents some category, which the Scholastics called praedicatum in Latin and which became predicate in English. If necessary, the verb form is may be replaced by are, has, or have in order to make grammatical English sentences. Although the patterns may look like English, they are limited to a highly constrained syntax and semantics: each sentence has exactly one quantifier, at most one negation, and a single predicate that is true or false of the individuals indicated by the subject.
Although Aristotle's syllogisms are the oldest version of formal logic, they are still an important subset of logic, which forms the foundation for description logics, such as DAML and OIL. For frame-like inheritance, the major premise is a universal affirmative statement with the connecting verb is; the minor premise is a universal or particular affirmative with is, has, or other verbs. Many constraints for a DBMS or an expert system can be stated as universal negative statement with any of the verbs. For constraint checking and constraint inheritance, the major premise is the constraint, and the minor premise is a statement in one of the other three patterns.
Another important version of logic is the Horn-clause subset, which is widely used for defining expert system rules and SQL views. The basic syntax has an if-then pattern: the if-part of the rule is a conjunction of one or more statements, which may have some negations; the then-part is a conjunction of one or more statements, which may not have negations. Following are two such rules for a library database, written in Attempto Controlled English (Fuchs et al. 1998; Schwitter 1998):
If a copy of a book is checked out to a borrower and a staff member returns the copy then the copy is available.
If a staff member adds a copy of a book to the library
and no catalog entry of the book exists
then the staff member creates a catalog entry
that contains the author name of the book
and the title of the book
and the subject area of the book
and the staff member enters the id of the copy
and the copy is available.
The Attempto system translates these rules to an executable form
in Prolog. Anyone who can read English can read controlled English
as if it were English, but controlled languages are formal languages
that require some training for an author to stay within their limitations.
Section 3 of this paper discusses tools that can guide an author
to avoid the ambiguities of full natural language or help
a human editor to clarify them.
In the late 19th century, three logically equivalent, but structurally very different notations for first-order logic (FOL) were developed. The first was the tree-like Begriffsschrift by Frege (1879), and the second was the algebraic notation by Peirce (1880, 1885). With minor modifications by Peano (1889), Peirce's version became the most commonly used notation for logic during the 20th century. The third notation was Peirce's existential graphs of 1897, which he called his chef d'oeuvre. KIF is a sorted version of Peirce's algebraic notation, and conceptual graphs are a sorted version of Peirce's graph notation. For comparison, Figure 1 is a CG representation of the controlled English sentence, John is going to Boston by bus.
Figure 1: A conceptual graph in the display form
The boxes in Figure 1 are called concepts, and the circles are called conceptual relations. The default quantifier for each concept is the existential, which says that something of the specified type exists; the concept [City: Boston] means that there exists a city, which is named Boston. Each conceptual relation has one or more arcs: (Agnt) links a concept that represents an action to the concept that represents its agent; (Inst) links the action to its instrument; and (Dest) links an action that involves motion to its destination. All the relations in Figure 1 are dyadic, but in general, a conceptual relation may have any number of arcs.
Although the display form is quite readable, it is not easy to type or to transmit across a network. Therefore, two interchange formats have been developed: the Conceptual Graph Interchange Format (CGIF) maps directly to and from the display form; and the Knowledge Interchange Format (KIF) maps directly to and from the algebraic notation for predicate calculus. Following is the CGIF representation of Figure 1:
[Go: *x] [Person: 'John' *y] [City: 'Boston' *z] [Bus: *w] (Agnt ?x ?y) (Dest ?x ?z) (Inst ?x ?w)This statement captures every detail of the display form except the two-dimensional layout, which is not semantically relevant. If desired, the layout information could be included as structured comments inside the brackets and parentheses that enclose the nodes of the graph. The connections between concepts and relations, which are shown directly by the arcs of the graph in Figure 1, are shown indirectly by labels, such as ?x and ?y in CGIF. Those labels are translated to variables in KIF, as in the following example:
(exists ((?x Go) (?y Person) (?z City) (?w Bus))
(and (Name ?y John) (Name ?z Boston)
(Agnt ?x ?y) (Dest ?x ?z) (Inst ?x ?w)))
KIF notation is used for many theorem provers and inference engines
that are based on predicate calculus. The translations between KIF
and CGIF preserve the semantics: a mapping from KIF to
CGIF and back to KIF might not generate an identical statement, but
it will generate a statement that is logically equivalent.
KIF and conceptual graphs can represent the full range of operators and quantifiers of first-order logic, and they have been extended with metalevel features that can be used to define extensions to FOL, including modal logic and higher-order logic. The metalevel features are necessary for representing the speech acts of Elephant 2000, which uses logic to talk about the use of logic. In natural languages, metalevels are marked by a variety of syntactic features that delimit the context of the metalanguage from the context the object language. The most obvious delimiters are quotation marks, but similar contexts are introduced by verbs that express what some agent says, thinks, believes, requests, wants, promises, or hopes. As an example, the following English sentence contains two nested levels, which are enclosed in brackets for emphasis:
Tom believes [Mary wants [to marry a sailor]].This sentence is represented by the CG in Figure 2.

Figure 2: A conceptual graph with two nested contexts
The context of Tom's belief is represented by a concept of type Proposition, which contains a nested CG that states the proposition. The context of Mary's desire is represented by a concept of type Situation, which is described by a proposition that is stated by the nested CG. The (Expr) relation represents the experiencer of a mental state, and the (Thme) relation represents the theme. In general, the theme of a belief or an assertion is a proposition, but the theme of a desire must be something physical, such as a situation. Following is the CGIF equivalent of Figure 2:
[Person: *x1 'Tom'] [Believe *x2] (Expr ?x2 ?x1)
(Thme ?x2 [Proposition:
[Person: *x3 'Mary'] [Want *x4] (Expr ?x4 ?x3)
(Thme ?x4 [Situation:
[Marry *x5] (Agnt ?x5 ?x3) (Thme ?x5 [Sailor]) ]) ])
And following is the equivalent KIF statement.
(exists ((?x1 person) (?x2 believe))
(and (name ?x1 'Tom) (expr ?x2 ?x1)
(thme ?x2
(exists ((?x3 person) (?x4 want) (?x8 situation))
(and (name ?x3 'Mary) (expr ?x4 ?x3) (thme ?x4 ?x8)
(dscr ?x8 (exists ((?x5 marry) (?x6 sailor))
(and (Agnt ?x5 ?x3) (Thme ?x5 ?x6)))))))))
The context boxes delimit the scope of quantifiers and other logical operators. The sailor, whose existential quantifier occurs inside the context of Mary's desire, which itself is nested inside the context of Tom's belief, might not exist in reality. Following is another sentence that makes it clear that the sailor does exist:
There is a sailor that Tom believes Mary wants to marry.This sentence corresponds to the CG in Figure 3.

Figure 3: A CG that asserts the sailor's existence
The English sentence mentions the sailor before introducing any verb that creates a nested context. Therefore, the concept [Sailor] in Figure 3, with its implicit existential quantifier, is moved outside any nested context. In the CGIF and KIF notations, the concept or the quantifier that refers to the sailor would be moved to the front of the statement. Another possibility, represented by the sentence Tom believes there is a sailor that Mary wants to marry, could be represented by moving the concept [Sailor] into the middle context, which represents Tom's belief. In CGIF and KIF, the corresponding concept or quantifier would also be moved to the context of Tom's belief.
As these examples illustrate, conceptual graphs in the display form are more readable than either CGIF or KIF. There are two reasons for the improved readability:
During the 1980s, the dominant approach to knowledge acquisition required two kinds of highly trained, highly paid professionals. At the top of Figure 4, a knowledge engineer is interviewing a subject matter expert in order to capture her knowledge and encode it in the arcane formats of an AI system. Meanwhile, computational linguists, who were designing natural-language tools, tried to make them translate NL documents into similar encodings without requiring any human intervention. At the bottom of Figure 4, a physician who is examining a patient scribbles some notes on a sheet of paper, which some clerk will later transcribe for the computer. Then the NL tools will attempt to convert those notes to the formats specified by the knowledge engineer.
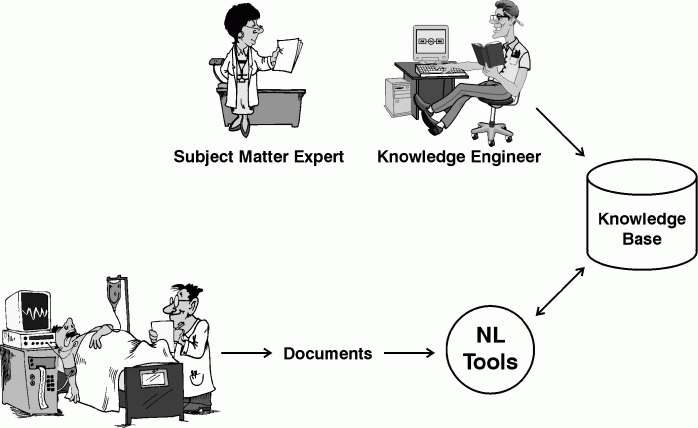
Figure 4: Twentieth century approaches to knowledge acquisition and NL processing
There are two things wrong with Figure 4: the top row requires far too much human effort, and the bottom row is expected to process unrestricted natural language without any human assistance. To reduce the cost of two high-priced experts, some developers merged the two roles at the top row into one: either the subject matter expert learned knowledge engineering, or the knowledge engineer learned enough about the subject matter to extract knowledge from documents. Yet people with expertise in both fields became even more expensive to find, hire, and train. Figure 5 shows a better alternative: simplify the tools and the training required by the people who use them. Instead of designing complex NL tools that process documents without human intervention, AI researchers developed simpler knowledge extraction (KE) tools that can extract knowledge from documents with assistance from just one human editor. Furthermore, the editor communicates with the KE tools in a controlled natural language, which people can read without special training.
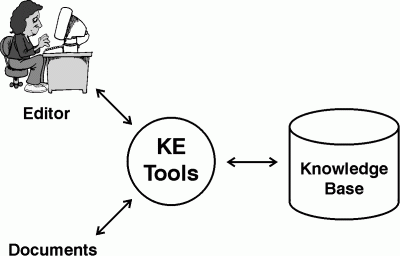
Figure 5: Replacing two experts with one editor
The editor in Figure 5 represents various people who at different times might play different roles with respect to the subject matter, the computer system, and the people and activities involved with them. Each of the three people in Figure 4 has a different kind of expertise. Any of them might use KE tools to edit their knowledge or to write a note, a report, or a book that someone else might edit with the aid of KE tools. Following are the three kinds of knowledge, the roles of the two experts in Figure 4, and the way that KE tools can help the editor in Figure 5 do the work of both:
As examples of KE tools, Doug Skuce (1995, 1998, 2000) has designed an evolving series of knowledge extraction systems, which he called CODE, IKARUS, and DocKMan (Document-based Knowledge Management). All the input to the knowledge base, whether generated by the KE tools or entered directly by an editor, is represented in a CNL called ClearTalk. The KE tools have the following advantages over the older systems represented by Figure 4:
Over the past thirty years, many natural-language query systems have been developed that are much easier to use than SQL. Unfortunately, one major stumbling block has prevented them from becoming commercially successful: the amount of effort required to define the vocabulary terms and map them to the appropriate fields of the database is a large fraction of the effort required to design the database itself. However, if appropriate KE tools are used to design the database, the vocabulary needed for the query system can be generated as a by-product of the design process. As an example, the RÉCIT system (Rassinoux 1994; Rassinoux et al. 1998) uses KE tools to extract knowledge from medical documents written in English, French, or German and translates the results to a language-independent representation in conceptual graphs. The knowledge extraction process defines the appropriate vocabulary, specifies the database design, and adds new information to the database. The vocabulary generated by the KE process is sufficient for end users to ask questions and get answers in any of the three languages.
Translating an informal diagram to a formal notation of any kind is as difficult as translating informal English specifications to executable programs. But it is much easier to translate a formal representation in any version of logic to controlled natural languages, to various kinds of graphics, and to executable specifications. Walling Cyre and his students have developed KE tools for mapping both the text and the diagrams from patent applications and similar documents to conceptual graphs (Cyre et al. 1994, 1997, 1999). Then they implemented a scripting language for translating the CGs to circuit diagrams, block diagrams, and other graphic depictions. Their tools can also translate CGs to VHDL, a hardware design language used to specify very high-speed integrated circuits (VHSIC).
Design and specification languages have multiple metalevels. As an example, the Unified Modeling Language has four levels: the metametalanguage defines the syntax and semantics of the UML notations; the metalanguage defines the general-purpose UML types; a systems analyst defines application types as instances of the UML types; finally, the working data of an application program consists of instances of the application types. To provide a unified view of all these levels, Olivier Gerbé and his colleagues at the DMR Consulting Group implemented design tools that use conceptual graphs as the representation language at every level (Gerbé et al. 1995, 1996, 1997, 1998, 2000). For his PhD dissertation, Gerbé developed an ontology for using CGs as the metametalanguage for defining CGs themselves. He also applied it to other notations, including UML and the Common KADS system for designing expert systems. Using that theory, Gerbé and his colleagues developed the Method Repository System as an authoring environment for editing, storing, and displaying the methods used by the DMR consultants. Internally, the knowledge base is stored in conceptual graphs, but externally, the graphs can be translated to web pages in either English or French. About 200 business processes have been modeled in a total of 80,000 CGs. Since DMR is a Canadian company, the language-independent nature of CGs is important because it allows the specifications to be stored in the neutral CG form. Then any manager, systems analyst, or programmer can read them in his or her native language.
No single system discussed in this paper incorporates all the features desired in a KE system, but the critical research has been done, and the remaining work requires more development effort than pure research. Figure 6 shows the flow of information from documents to logic and then to documents or to various computational representations. The dotted arrow from documents to controlled languages requires human assistance. The solid arrows represent fully automated translations that have been implemented in one or more systems.
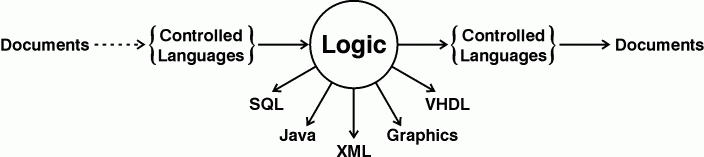
Figure 6: Flow of information from documents to computer representations
For all these tools, the unifying representation language is logic, which could be represented in KIF, CGs, or other notations specialized for various tools. Aristotelian syllogisms together with Horn-clause rules provide sufficient expressive power to specify a Turing machine, and they support efficient computational mechanisms for executing the specifications. For database queries and constraints, statements in full first-order logic can be translated to SQL. All these subsets, however, use the same vocabulary of natural-language terms, which map to the same ontology of concepts and relations. From the user's point of view, the system communicates in a subset of natural language, and the differences between tools appear to be task-related differences rather than differences in language.
For many purposes, graphs are a natural representation that is isomorphic to the structure of an application: maps with cities as nodes and highways as arcs; flow diagrams through programs, electrical wiring, and plumbing; the valence bonds between atoms of an organic molecule; the communication links in a computer network; the reference patterns between documents and web sites on the Internet; and the semantics of natural languages with their complex phrase structures and anaphoric references. When such networks are represented by strings or matrices, the resulting data structures tend to make inefficient use of storage space, execution time, or both. This section surveys five important components of an intelligent system that can benefit from graph-based algorithms:
During the 1970s, the database field was embroiled in a controversy between the proponents of the new relational DBMS, which stored data in tables, and the proponents of older DBMS systems, which stored data in networks or hierarchies. For many applications, the network and hierarchical systems had better performance, but the relational systems became the universal standard because their logic-based query languages, such as SQL, were far easier to use than the navigational systems, which required a link-by-link traversal of the networks. The battle for network DBMS was finally lost when one its staunchest defenders claimed that ease of use was not important because "programmers enjoy a challenge." Today, network systems have come back into vogue as the foundation for object-oriented DBMS, which represent the connections between objects more directly than the now standard RDBMS. Yet the query languages for OODBMS require the same kind of link-by-link traversals as the navigational methods of the 1970s. Unlike the logic-based SQL standard, the OODBMS query languages require far more programming effort, which must be specialized to the formats of each vendor.
To support a more natural interface between humans and computers, Sowa (1976, 1984) proposed conceptual graphs as an intermediate language between natural languages and logic-based computer languages. For question-answering systems, a CG derived from a natural language question could be translated to logic-based query languages such as SQL or be matched against the graphs of a network DBMS. In principle, CGs could provide a high-level interface for any DBMS — relational, network, or object-oriented. However, there were two obstacles to using CGs as the universal interface to every DBMS: the natural language processors were not sufficiently robust to generate them, and the algorithms for generating answers from network databases were too slow.
The breakthrough in performance that made a CG database efficient was accomplished by Levinson and Ellis (1992), who developed algorithms that could search a lattice of graphs in logarithmic time. Instead of navigating the networks link by link, their systems could take any query graph q and determine where it fit within the lattice. As a result, it would return two pointers: one would point to the lower sublattice of all graphs that are more specialized than q, and the other would point to the upper sublattice of all graphs that are more generalized than q.
For deduction and theorem proving, Peirce (1897, 1909) discovered graph-based rules of inference, which are generalizations and simplifications of the rules of natural deduction by Gentzen (1935). The beauty of Peirce's rules is that they make a perfect fit with a system that stores and retrieves graphs in a generalization hierarchy: Peirce's rules are based on the conditions in which any graph p may be replaced by a generalization of p or a specialization of p. Furthermore, the negation of any context reverses the ordering for all graphs in the context: if p is a generalization of q, then ~p is a specialization of ~q. Esch and Levinson (1995, 1996) presented algorithms for combining Peirce's rules with search and retrieval from a generalization hierarchy, and one of Levinson's students, Stewart (1996), implemented those algorithms in a high-speed theorem prover for first-order logic. Every proposition that was proved, either as a theorem or as an intermediate result, was stored in its appropriate place in the generalization hierarchy together with a pointer to its proof. During a proof, each possible step that could be generated by Peirce's rules was used as a query graph q to determine whether q or any specialization of q had already been proved. If so, the proof was done.
A high-speed search and retrieval mechanism for generalization hierarchies of graphs can also be used as the basis for structural learning algorithms. Unlike neural networks and statistical algorithms, whose learning consists of changing numerical weights, a graph-based algorithm can learn arbitrarily large structures represented as graphs. To demonstrate that principle, Levinson (1996) used his search algorithms in a learning program that would learn to play board games, such as chess, by starting with no knowledge about the game other than the ability to make legal moves. His chess program, called Morph, learned chess by playing games with a tutor called Gnu Chess, which was a master-level program, but it could not improve its performance by learning. At the end of each game, Morph was told whether the game was won, lost, or drawn (usually lost, especially in the early stages of learning). Then Morph would estimate the values of all the intermediate positions achieved during the game by backpropagation from the final value (1.0 for a win, 0.5 for a draw, or 0 for a loss), and save the chess positions with their estimated values as graphs in the hierarchy. When it made a move, Morph would determine all the possible moves, look up the corresponding positions in the hierarchy, find the closest matching positions, and consider their previously estimated values. Morph would then make the move that led to the position with the best estimated value. After playing a few thousand games with its tutor, Morph would have a sufficient database of moves with estimated values to play a decent game of chess.
To find analogies, Majumdar (2001) implemented a system called VivoMind, which represents knowledge in dynamic conceptual graphs. What makes the graphs dynamic are algorithms that pass messages along the nodes of a graph. Each node in a CG corresponds to an object that can pass messages to neighboring nodes. The result is an elegant generalization of the marker-passing algorithms originally implemented by Quillian (1966) and further developed by Fahlman (1979) and Hendler (1987). For finding analogies, VivoMind has proved to be as good or better than other analogical reasoners on all the usual test cases. It is also far more efficient computationally.
The contexts of conceptual graphs are based on Peirce's logic of existential graphs and his theory of indexicals. Yet the CG contexts happen to be isomorphic to the similarly nested discourse representation structures (DRS), which Hans Kamp (1981a,b) developed for representing and resolving indexicals in natural languages. When Kamp published his first version of DRS, he was not aware of Peirce's graphs. When Sowa (1984) published his book on conceptual graphs, he was not aware of Kamp's work. Yet the independently developed theories converged on semantically equivalent representations; therefore, Sowa and Way (1986) were able to apply Kamp's techniques to conceptual graphs. Such convergence is common in science; Peirce and Frege, for example, started from very different assumptions and converged on equivalent semantics for FOL, which 120 years later is still the most widely used version of logic. Independently developed, but convergent theories that stand the test of time are a more reliable basis for standards than the consensus of a committee.
Although graphs are one of the most versatile representations, many good tools use other notations. A framework for intelligent systems should take advantage of different structural properties: some algorithms are more efficient on graphs, and some algorithms are more efficient on strings or tables. The logical equivalence of KIF and CGIF facilitates the mapping from one to the other. Their generality facilitates the integration with other languages that have more restricted expressive power, such as SQL, DAML, OIL, RDF, and others. Components based on any of those languages can be integrated with a system that uses KIF and CGs as its primary languages.
The limitations of AI systems have often been blamed on the complexity of the required computations. Various solutions have been proposed, ranging from highly parallel networks that mimic the mechanisms of the human brain to restricted languages that limit the complexity of the problem definition. A modular architecture could support components that use such strategies for special purposes: neural networks, for example, have been highly successful for pattern recognition, and restricted languages can be highly efficient for specific kinds of problems. For central communications among all components, however, the Elephant language used in the blackboard must be the most expressive, since it must transmit any information that any other component might use or generate. That extreme expressive power raises a question about the complexity of the computations needed to process it.
Computational complexity, however, is not a property of a language, but a property of the problems stated in that language. First-order logic has been criticized as computationally intractable because the proof of an arbitrary FOL theorem may take an exponentially increasing amount of time. That criticism, however, is misleading, since large numbers of problems stated in full FOL are easily solvable. Placing restrictions on the logic or the notation cannot make an intractable problem solvable; they merely make it impossible to state. The expressive power of Elephant does not slow down the communications from one component to another. The components that receive a communication are responsible for determining what they can do with it.
For certain kinds of problems, first-order logic can be the most efficient way to express them and to solve them. A typical example is answering a query in terms of a relational database. The answer to an SQL query that uses the full expressive power of FOL can be evaluated in at most polynomial time, with the exponent of the polynomial equal to the number of quantifiers in the query. If the quantifiers range over an indexed domain, the evaluation can often be done in logarithmic time. Evaluating a constraint against a relational database is just as efficient as evaluating a query; in fact, every constraint can be translated to a corresponding query that asks for all instances in the database that violate the constraint. In commercial SQL systems, queries and constraints with the expressive power of FOL are routinely evaluated with databases containing gigabytes and terabytes of data.
Although the time to solve an intractable problem may be very long, the time to detect the complexity class of a problem can be very short. Callaghan (2001) took advantage of syntactic criteria to subdivide the Levinson-Ellis graph hierarchies into several disjoint subhierarchies, each of which is limited to one complexity class. For each subhierarchy, he determined appropriate algorithms for efficiently classifying and searching that hierarchy. To determine the complexity class of any graph, Callaghan computed a signature or descriptor to determine its complexity properties. Each graph's descriptor would specify easily computable prerequisites (necessary conditions) that any matching graph must meet. By precomputing the descriptor of a query graph, Callaghan accomplished several goals at once: determining the complexity of the search (tractability or decidability); narrowing the search to a particular class of graphs that have compatible descriptors; or determining whether the query graph lies outside the known complexity classes.
Besides the subhierarchies of graphs supported by the Levinson-Ellis algorithms, Callaghan's approach can accommodate any external subsystem for which a suitable descriptor can be computed by simple syntactic tests. Among those subsystems are the relational databases, which are highly optimized for data stored in tables. In fact, the Levinson-Ellis hierarchies are complementary to an RDBMS: the kinds of data that are most efficient with one are the least efficient with the other. Other important subsystems include the specialized query languages of many versions of description logics. If a query graph lies outside of any of the known classes, it can be sent to a general first-order theorem prover. As a result, this approach can accept any query expressible in first-order logic, determine its complexity class, and send it to the most efficient subsystem for processing it.
Mapping a smaller logic to a more expressive logic is always possible, but the reverse mapping usually requires some restrictions. To map information from a large, rich knowledge base to a smaller, more efficiently computable one, Peterson, Andersen, and Engel (1998) developed a system they called the knowledge bus. Their source was the CYC knowledge base (Lenat & Guha 1990; Lenat 1995), which contains over 500,000 axioms expressed in full FOL with temporal, higher-order, and nonmonotonic extensions. Their target was a hybrid system that combined a relational database with an inference engine based on the Horn-clause subset of FOL. To map from one to the other, the knowledge bus performs the following transformations:
A framework based on Elephant and Linda would subsume anything that could be done with a more conventional scripting language. Natural languages can specify procedures with a sequence of imperative statements linked by adverbs like then and next. A translation of those statements into KIF or CGs would specify the same procedure. But natural languages and their translations into logic could also specify more complex speech acts that could dynamically reconfigure the components of an intelligent system and their ways of interacting.
In the original Linda system, the operators access a blackboard that contains tuples, which consist of sequences of arbitrary data. For a system that supports multiple languages, the first element of the tuple should identify the language so that the Linda system could immediately determine how to interpret the remainder. A general format would have six elements:
The Linda pattern matcher could use an ordinary string comparison for the first five elements of the tuple, but it would require a more general logical unification (of CGs or KIF statements) for the sixth. Unification of messages in controlled natural languages might be difficult to define, and the pattern matcher might need to translate the message to CGs or KIF if a pattern match is necessary.
To simulate a conventional scripting language, the destination would always be specified, and the speech act would always be "command". To access a relational database, the speech act would be "assertion" for an update, "question" for a query, or "definition" for creating a new table with a new format. At the end of his book, Austin (1962) specified a large number of possible speech acts, and he insisted that his list was not exhaustive. Following are his five categories, his description of each, and a few of his examples:
Examples: acquit, convict, calculate, estimate, measure, assess, characterize, diagnose.
Examples: appoint, demote, excommunicate, command, direct, bequeath, claim, pardon, countermand, veto, dedicate.
Examples: promise, contract, undertake, intend, plan, propose, contemplate, engage, vow, consent, champion, oppose.
Examples: apologize, thank, deplore, congratulate, welcome, bless, curse, defy, challenge.
Examples: affirm, deny, state, assert, ask, identify, remark, mention, inform, answer, repudiate, recognize, define, postulate, illustrate, explain, argue, correct, revise, tell, report, interpret.
The verbs listed in these examples illustrate the kinds of speech acts that people commonly perform, but in most cases, they omit the verb that specifies the speech act. A man who stands up in a meeting to shout something in an angry voice seldom begins with the words "I protest." Yet the people in the audience would recognize that the new speaker is protesting rather than agreeing with the previous speakers. Computers, however, need to be told how to interpret such speech, and an explicit statement of the speech act would enable them to respond more "intelligently."
To illustrate the kinds of speech acts in an AI system, Figure 7 shows a kind of system discussed by Sowa (2000). The boxes labeled FMF represent the same flexible modular framework that has been adapted to different kinds of tasks by changing the roles and the kinds of speech acts expected of the users. At the upper left, logicians, linguists, and philosophers are using the FMF to define a general ontology. Logicians could use FMF to enter the definitions and axioms for logical operators, set theory, and basic mathematical concepts and relations. Linguists could use it to enter the grammar rules of natural languages and the kinds of semantic types and relations. Philosophers could use FMF to collaborate with the linguists and logicians in analyzing and defining the fundamental ontologies of space, time, and causality common to all domains of application. The major speech act for these users would be definition, but they might also ask questions about how to use the system, and they might use verdictives to evaluate the work of their colleagues.

Figure 7: Tailoring an FMF for different purposes
In the center of Figure 7, application developers use FMF to enter domain-dependent information about specific applications. Some of them would use FMF to define generic ontologies for industries such as banking, agriculture, mining, education, and manufacturing. Others would start with one or more generic ontologies and combine them or tailor them to a particular business, project, or application. The users in this mode would perform the same kinds of speech acts as the logicians, linguists, and philosophers. But they might put more emphasis on commissives, which would commit them to strict deadlines and performance goals.
At the bottom right of Figure 7 the application users might interact with the FMF in an unpredictable number of ways. A business user with a job to do would have different requirements from a recreational user. Both, however, might react with behabitives, such as grumbling, complaining, or cursing, when the system doesn't do what they wish. But unlike more conventional systems, an FMF could apologize, sympathize, and commiserate.
The examples shown in Figure 7 do not begin to expoit the kinds of opportunities offered by an FMF that is able to recognize and respond to a wide range of speech acts. An important reason for building an FMF is to explore new ways of interaction, either between computers and humans or among mixed committees of human and computer participants. The explicit recognition and marking of speech acts enables the components of an FMF to interact, negotiate, and cooperate more intelligently among themselves and with their human users.
A major advantage of a flexible modular framework is that it doesn't have to be implemented all at once. The four design principles, which enabled Unix-like systems to be implemented on anything from a wearable computer to the largest supercomputers, can also support the growth of intelligent systems from simple beginnings to a large "society of mind," as Minsky (1985) called it. For an initial implementation, each of the four principles could be reduced to the barest minimum, but any of them could be enhanced incrementally without disturbing any previously supported operations:
A blackboard is an ideal platform for supporting hot-swap or plug-n-play components. When a new component is added to the FMF, it would send a message to the blackboard to identify itself and the patterns of messages it accepts. It could then be invoked by any other component whose message matches the appropriate pattern. To take advantage of that flexibility, the Jini system uses the Linda operators to accommodate any kind of I/O device that might be attached to a network. But for intelligent systems, it is even more important to have that flexibility at the center instead of the periphery.
Any server anywhere on the Internet could be converted to an intelligent agent by using an FMF as its front end. It could then respond to requests from other FMF servers anywhere else on the Internet. Each FMF would be, in Minsky's terms, a society of mind, and the entire Internet would become a society of societies. Human users could have a personal FMF running on their own computers, which could communicate with any other FMF to request services. The traditional help desks, in which a human expert answers the same questions repeatedly for multiple users, could be replaced by a human teacher or editor, as in Figure 5, who would build a knowledge base. That knowledge base would drive a specialized FMF, which could be consulted by the personal FMF of anyone who asks a relevant question. The intelligence accessible to any user would then be the combined intelligence of his or her personal FMF together with every FMF accessible to it across the Internet.
Austin, John L. (1962), How to do Things with Words, second edition edited by J. O. Urmson & Marina Sbisá, Harvard University Press, Cambrige, MA, 1975.
Carriero, Nicholas, & David Gelernter (1992) How to Write Parallel Programs, MIT Press, Cambridge, MA.
Cyre, W. R., S. Balachandar, & A. Thakar (1994) "Knowledge visualization from conceptual structures," in Tepfenhart et al. (1994) Conceptual Structures: Current Practice, Lecture Notes in AI 835, Springer-Verlag, Berlin, pp. 275-292.
Cyre, W. R. (1997) "Capture, integration, and analysis of digital system requirements with conceptual graphs," IEEE Trans. Knowledge and Data Engineering, 9:1, 8-23.
Cyre, W. R., J. Hess, A. Gunawan, & R. Sojitra (1999) "A Rapid Modeling Tool for Virtual Prototypes ," in 1999 Workshop on Rapid System Prototyping, Clearwater, FL.
Ellis, Gerard (1992) "Compiled hierarchical retrieval," in T. Nagle, J. Nagle, L. Gerholz, and P. Eklund, eds., Conceptual Structures: Current Research and Practice, Ellis Horwood, New York, pp. 271-294.
Ellis, Gerard, Robert A. Levinson, & Peter J. Robinson (1994) "Managing complex objects in Peirce," International J. of Human-Computer Studies, vol. 41, pp. 109-148.
Engel, Joshua (1999) Programming for the Java Virtual Machine, Addison-Wesley, Reading, MA.
Esch, John, & Robert A. Levinson (1995) "An Implementation Model for Contexts and Negation in Conceptual Graphs", in G. Ellis, R. A. Levinson, & W. Rich, eds., Conceptual Structures: Applications, Implementation, and Theory, Lecture Notes in AI 954, Springer-Verlag, Berlin, pp. 247-262.
Esch, John, & Robert A. Levinson (1996) "Propagating Truth and Detecting Contradiction in Conceptual Graph Databases," in P. W. Eklund, G. Ellis, & G. Mann, eds., Conceptual Structures: Knowledge Representation as Interlingua, Lecture Notes in AI 1115, Springer-Verlag, Berlin, pp. 229-247.
Fahlman, Scott E. (1979) NETL: A System for Representing and Using Real-World Knowledge, MIT Press, Cambridge, MA.
Gentzen, Gerhard (1935) "Untersuchungen über das logische Schließen," translated as "Investigations into logical deduction" in The Collected Papers of Gerhard Gentzen, ed. and translated by M. E. Szabo, North-Holland Publishing Co., Amsterdam, 1969, pp. 68-131.
Gerbé, Olivier, & M. Perron (1995) "Presentation definition language using conceptual graphs," in G. Ellis, R. A. Levinson, & W. Rich, eds., Conceptual Structures: Applications, Implementation, and Theory, Lecture Notes in AI 954, Springer-Verlag, Berlin.
Gerbé, Olivier, B. Guay, & M. Perron (1996) "Using conceptual graphs for methods modeling," in P. W. Eklund, G. Ellis, & G. Mann, eds., Conceptual Structures: Knowledge Representation as Interlingua, Lecture Notes in AI 1115, Springer-Verlag, Berlin, pp. 161-174.
Gerbé, Olivier (1997) "Conceptual graphs for corporate knowledge management," in D. Lukose, H. Delugach, M. Keeler, L. Searle, & J. Sowa, eds., Conceptual Structures: Fulfilling Peirce's Dream, Lecture Notes in AI 1257, Springer-Verlag, Berlin, pp. 474-488.
Gerbé, Olivier, R. Keller, & G. Mineau (1998) "Conceptual graphs for representing business processes in corporate memories," in M-L Mugnier & Michel Chein, eds., Conceptual Structures: Theory, Tools, and Applications, Lecture Notes in AI 1453, Springer-Verlag, Berlin, pp. 401-415.
Gerbé, Olivier, & Brigitte Kerhervé (1998) "Modeling and metamodeling requirements for knowledge management," in Proc. of OOPSLA'98 Workshops, Vancouver.
Gerbé, Olivier (2000) Un Modèle uniforme pour la Modélisation et la Métamodélisation d'une Mémoire d'Entreprise, PhD Dissertation, Département d'informatique et de recherche opérationelle, Université de Montréal.
Hansen, Hans Robert, Robert Mühlbacher, & Gustaf Neumann (1992) Begriffsbasierte Integration von Systemanalysemethoden, Physica-Verlag, Heidelberg. Distributed by Springer-Verlag.
Hendler, James A. (1987) Integrating Marker Passing and Problem Solving, Lawrence Erlbaum Associates, Hillsdale, NJ.
Hess, J. & W. Cyre (1999) "A CG-based Behavior Extraction System," in W. Tepfenhart & W. Cyre, eds. (1999) Conceptual Structures: Standards and Practices, Lecture Notes in AI 1640, Springer-Verlag, Berlin.
Kamp, Hans (1981a) "Events, discourse representations, and temporal references," Langages 64, 39-64.
Kamp, Hans (1981b) "A theory of truth and semantic representation," in Formal Methods in the Study of Language, ed. by J. A. G. Groenendijk, T. M. V. Janssen, & M. B. J. Stokhof, Mathematical Centre Tracts, Amsterdam, 277-322.
Kamp, Hans, & Uwe Reyle (1993) From Discourse to Logic, Kluwer, Dordrecht.
Kerhervé, Brigitte, & Olivier Gerbé (1997) "Models for metadata or metamodels for data?" in Proc. 2nd IEEE Metadata Conference, Silver Spring.
Lenat, Douglas B. (1995) "CYC: A large-scale investment in knowledge infrastructure," Communications of the ACM 38:11, 33-38. For further information, see http://www.cyc.com.
Lenat, Douglas B., & R. V. Guha (1990) Building Large Knowledge-Based Systems, Addison-Wesley, Reading, MA.
Levinson, Robert A., & Gerard Ellis (1992) "Multi-level hierarchical retrieval," Knowledge-Based Systems, vol. 5, no. 3, 1992.
Levinson, Robert A. (1996) "General game-playing and reinforcement learning," Computational Intelligence 12:1 155-176.
Majumdar, Arun (2001) "About VivoMind," http://www.genumerix.com/rfi/AboutVivoMind.htm
McCarthy, John (1989) "Elephant 2000: A programming language based on speech acts," http://www-formal.stanford.edu/jmc/elephant.html
Minsky, Marvin (1985) The Society of Mind, Simon & Schuster, New York.
Pazienza, Maria Teresa, ed. (1999) Information Extraction: Towards Scalable, Adaptable Systems, LNAI #1714, Springer-Verlag, Berlin.
Peano, Giuseppe (1889) Aritmetices principia nova methoda exposita, Bocca, Torino.
Peirce, Charles Sanders (1880) "On the algebra of logic," American Journal of Mathematics 3, 15-57. Reprinted in W 4:163-209.
Peirce, Charles Sanders (1885) "On the algebra of logic," American Journal of Mathematics 7, 180-202. Reprinted in W 5:162-190.
Peirce, Charles Sanders (1897-1906) Manuscripts on existential graphs. Some are reprinted in CP 4.320-410; others are summarized by Roberts (1973).
Peirce, Charles Sanders (1909) Manuscript 514, with commentary by J. F. Sowa, available at http://www.jfsowa.com/peirce/ms514.htm
Peirce, Charles Sanders (CP) Collected Papers of C. S. Peirce, ed. by C. Hartshorne, P. Weiss, & A. Burks, 8 vols., Harvard University Press, Cambridge, MA, 1931-1958.
Peirce, Charles Sanders (W) Writings of Charles S. Peirce, vols. 1-6, Indiana University Press, Bloomington, 1982-1993.
Peterson, Brian J., William A. Andersen, & Joshua Engel (1998) "Knowledge bus: generating application-focused databases from large ontologies," Proc. 5th KRDB Workshop, Seattle, WA. Available from http://sunsite.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-10/.
Quillian, M. Ross (1966) Semantic Memory, abridged version in M. Minsky, Semantic Information Processing, MIT Press, Cambridge, MA, pp. 227-270.
Rassinoux, Anne-Marie (1994) Extraction et Représentation de la Connaissance tirée de Textes Médicaux, Éditions Systèmes et Information, Geneva.
Rassinoux, Anne-Marie, Robert H. Baud, Christian Lovis, Judith C. Wagner, Jean-Raoul Scherrer (1998) "Tuning up conceptual graph representation for multilingual natural language processing in medicine," in M-L Mugnier & M. Chein, eds. (1998) Conceptual Structures: Theory, Tools, and Applications, Lecture Notes in AI 1453, Springer-Verlag, Berlin, pp. 390-397
Roberts, Don D. (1973) The Existential Graphs of Charles S. Peirce, Mouton, The Hague.
Searle, John R. (1969), Speech Acts. An Essay in the Philosophy of Language, Cambridge University Press, Cambridge.
Skuce, Doug, & Timothy Lethbridge (1995) "CODE4: A unified system for managing conceptual knowledge," International J. of Human-Computer Studies, 42 413-451.
Skuce, Doug (1998) "Intelligent knowledge management: integrating documents, knowledge bases, and linguistic knowledge," in Proceedings of KAW'98, Calgary.
Skuce, Doug (2000) "Integrating web-based documents, shared knowledge bases, and information retrieval for user help," Computational Intelligence 16:1.
Sowa, John F. (1976) "Conceptual graphs for a database interface," IBM Journal of Research and Development 20:4, 336-357.
Sowa, John F. (1984) Conceptual Structures: Information Processing in Mind and Machine, Addison-Wesley, Reading, MA.
Sowa, John F. (1999) "Relating templates to language and logic," in Pazienza (1999) pp. 76-94.
Sowa, John F. (2000) Knowledge Representation: Logical, Philosophical, and Computational Foundations, Brooks/Cole, Pacific Grove, CA.
Sowa, John F., & Eileen C. Way (1986) "Implementing a semantic interpreter using conceptual graphs," IBM Journal of Research and Development 30:1, 57-69.
Stewart, John (1996) Theorem Proving Using Existential Graphs, MS Thesis, Computer and Information Science, University of California at Santa Cruz.
Copyright 2002, John F. Sowa
Last Modified: