
Figure 1: CG for Yojo is chasing a mouse.
VivoMind LLC
Abstract. Text understanding requires knowledge of the language and knowledge of the subject matter. During the past 40 years, many ways of using both kinds of knowledge have been implemented for natural language processing (NLP). This paper recommends a method called task-oriented semantic interpretation (TOSI), which combines a broad, but shallow lexical semantics with a narrow, but deep axiomatized semantics specialized for a particular task. To enable the system to process all information with common mechanisms, both kinds of knowledge are represented in conceptual graphs (CGs), and both are used in the same way to interpret input text. The primary difference is that the CGs associated with a specialized task may trigger additional processes to perform further reasoning or to execute application programs. TOSI was successfully used for legacy re-engineering, and it can also derive CGs customized for molecular biology from published papers or abstracts.
Semantic interpretation is the process of transforming a syntactic representation of a sentence into a logical form that represents its meaning. That process requires a great deal of background knowledge in order to resolve ambiguities and to determine implications that would be obvious to a human reader. Sometimes, the information needed to resolve an ambiguity comes from a context that spans more than one sentence, as in the following example:
John went to the board.This sentence has an unambiguous syntax, but the word board has multiple meanings or senses. The correct word sense may have been implied by a previous sentence, but often it may depend on the subsequent sentence:
Besides determining word senses, background knowledge is necessary to determine unspoken implications, which Grice (1975) called conversational implicatures. In the following conversation, adapted from one of Grice's examples, a driver stops to ask a question:
Driver: Where is the nearest gas station?A short while later, the driver comes back:Pedestrian: Turn right at the corner and go about two blocks.
D: Thanks.
The pedestrian was either deliberately perverse or totally uninformed about the purpose of a gas station. Unfortunately, such behavior is typical of most computer systems. They lack the two kinds of background knowledge that people normally use to understand language. The first example illustrates the importance of lexical knowledge for resolving ambiguities, and the second example illustrates the importance of task-oriented knowledge about such things as cars, drivers, and gas stations.D: That gas station is closed.
P: Yes. It hasn't been open for years.
D: Why didn't you tell me?
P: You didn't ask.
Natural languages evolved for efficient communication among people who could assume a great deal of common knowledge about typical human activities, culture, environment, and patterns of expression. Interpreting those languages by computer requires similar knowledge organized in some way that would enable a program to use it effectively. Several methods for organizing knowledge have been proposed and implemented in various AI systems:
The remainder of this paper presents knowledge soup as the general framework, and TOSI as a simplified version that has been implemented in a parser and semantic interpreter called Intellitex. This version has been used to process English as well as computer languages, such as COBOL, FORTRAN, and SQL. Different languages require different grammars, but the semantic interpreter can process information expressed in any language, natural or artificial. The example discussed in Section 5 of this paper shows the importance of that generality: Intellitex was used to analyze 1.5 million lines of COBOL programs and 100 megabytes of English documentation about those programs. Section 6 shows how the background knowledge used for semantic interpretation can be derived from English texts on molecular biology.
Conceptual graphs (CGs) are a highly expressive form of logic that was designed for representing natural-language semantics (Sowa 1984, 2000). The logical structure of CGs is based on a typed extension of the existential graphs by Peirce (1909) with additional features derived from the semantic networks of AI and from logics used to represent natural-language semantics. Since conceptual graphs have been well documented in the literature, just a few examples are shown here to illustrate the notation. The first example, Figure 1, shows a conceptual graph which represents the sentence Yojo is chasing a mouse.
Figure 1: CG for Yojo is chasing a mouse.
Figure 1 has three concepts, which are drawn as boxes, and two conceptual relations, which are drawn as circles. The concept [Cat: Yojo] represents a cat named Yojo; [Chase] represents an instance of chasing; and [Mouse] represents a mouse. The conceptual relation (Agnt) indicates that Yojo is the agent of chasing, and (Thme) indicates that the mouse is the theme or the one that is being chased. The CG is logically equivalent to the following formula in typed predicate calculus:
(∃x:Cat)(∃y:Chase)(∃z:Mouse) (name(x,"Yojo") ∧ agnt(y,x) ∧ thme(y,z)).This formula says that there exists a cat x, an instance of chasing y, and a mouse z; the name of x is "Yojo", the agent of y is x, and the theme of y is z. Both conceptual graphs and predicate calculus have equivalent model-theoretic semantics, and either notation can be automatically translated to the other while preserving the semantics.
Natural languages have context-dependent features that are not available in most versions of logic. As an example, the following short story uses pronouns, tenses, and cross references that span more than one sentence:
At 10:17 UTC, there was a cat named Yojo and a mouse. Yojo chased the mouse. Then he caught the mouse. Then he ate the head of the mouse.The time 10:17 UTC may be assumed as the approximate time of the situation described by the entire paragraph. In Figure 2, the concept box of type Situation is linked by the point-in-time relation (PTim) to a concept of the specified time. Any such concept that contains nested CGs is called a context. Nested inside the large context are three smaller contexts, which contain nested CGs derived from the second, third, and fourth sentences of the paragraph. Each context is linked to the next one by a relation of type Next. At the bottom of Figure 2, the patient relation (PTNT) links [Eat] to [Head]. The theme and the patient relations are both used to link the concept of an action to the concept of the thing that is acted upon. The theme of a verb (e.g. chase or catch) is not changed by the action, but the patient of a verb (e.g. eat) is substantially changed.

Figure 2: Nested contexts with unresolved references
Six of the concept nodes in Figure 2 have the indexical marker #, which indicates an unresolved reference. Three concepts of the form [Mouse: #], which may be read the mouse, refer to some previously mentioned mouse — in this example, to the concept [Mouse] in the outer box, which represents the first introduction by the phrase a mouse. The two concepts of the form [Animate: #he] represent the pronoun he, and the concept [Head: #] represents the phrase the head. Since predicate calculus has no way of marking indexicals, every occurrence of the symbol # must be replaced by links or labels to make the references explicit. To mark the first introduction or defining node for an entity, Figure 3 introduces the coreference labels *x for Yojo and *y for the mouse. Subsequent references use the same labels, but with the prefix ? in the bound occurrences of [?x] for Yojo and [?y] for the mouse. The # symbol in the concept [Head: #] of Figure 2 is erased in Figure 3, since the head of a normal mouse is uniquely determined when the mouse itself is identified.

Figure 3: Nested situations with references resolved
The contexts of conceptual graphs are based on Peirce's logic of existential graphs and his theory of indexicals. Yet the CG contexts happen to be isomorphic to the similarly nested discourse representation structures (Kamp & Reyle 1993). As a result, the techniques developed for the DRS notation can be applied to the CG notation in order to resolve indexicals. After the indexicals have been resolved to coreference labels, Figure 3 can be translated to the following formula in predicate calculus:
(∃s1:Situation)(pTim(s1,"10:17 UTC")
∧ dscr(s1,
(∃s1,s2,s3:Situation)(∃x:Cat)(∃y:Mouse)(name(x,"Yojo")
∧ dscr(s2, (∃u:Chase)(agnt(u,x) ∧ thme(u,y)))
∧ dscr(s3, (∃v:Catch)(agnt(v,x) ∧ thme(v,y)))
∧ dscr(s4,
(∃w:Eat)(∃z:Head)(agnt(w,x) ∧ ptnt(w,z) ∧ part(y,w)))
∧ next(s2,s3) ∧ next(s3,s4)))).
The description predicate dscr(s,p), which
corresponds to the context boxes of Figure 3, is a metalevel relation
between a situation s and a proposition p that describes
s. Figure 3 or its translation to predicate calculus could also
be paraphrased in a version of controlled English that uses variables
to show coreference explicitly: At 10:17 UTC, there was a situation s
involving a cat x named Yojo and a mouse y. In the situation s,
x chased y; then x caught y; then x ate the head of y.
Formally, CGs are semantically equivalent to other highly expressive systems of logic. Computationally, their graph structure supports efficient algorithms for the major operations of an intelligent system:
To accommodate the flexibility and adaptability of natural languages, a knowledge base must be as flexible and adaptable as the human brain. As an approximation to that flexibility, the knowledge soup is organized as an open-ended framework that can represent any information on any subject and multiple, dynamically changing, and possibly contradictory views of the same subject. Besides accommodating any kind of knowledge, it must be able to support logical deduction on those subjects that are sufficiently well defined and informal methods of analogy for those subjects that are still vague, uncertain, or even contradictory. Figure 4 illustrates some of the issues.
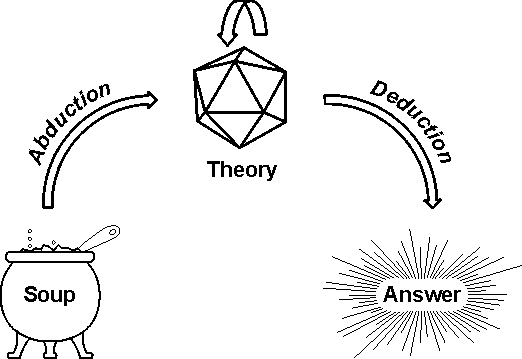
Figure 4: Crystallizing theories out of knowledge soup
On the left of Figure 4 is the knowledge soup, which contains a fluid, dynamically changing mix of information, consisting of some formally defined chunks floating in a richly interconnected broth of looser associations. The crystal at the top represents a formal theory, which may have been extracted as a unified whole from the soup, but which was more likely constructed from multiple chunks assembled and tailored by methods of theory revision. Since the theories usually represent some agent's beliefs, the term belief revision is used as a synonym for theory revision.
On the right is an answer to some problem or question, and the arrow shows that it was derived from the theory by deduction. Formal theories and methods of deduction have been implemented in AI systems for the past forty years. Theory revision represented by the arrow at the top, has been implemented in AI for nearly twenty years. The difficult part of Figure 4 is the arrow at the left labeled abduction. Peirce coined that term a century ago for the process of forming a guess or hypothesis about the information that might serve as a promising starting point for deduction. Peirce's suggestions have been implemented in various AI systems, but guessing is not easy to formalize in an algorithm.
Any attempt to constrain the knowledge soup or make it conform to a predefined ontology would destroy its most important feature: its limitless flexibility and adaptability to any and every view that is humanly conceivable. Instead of constraining it, a better approach is to let it expand into an open-ended, potentially infinite lattice — a mathematical structure that can accommodate every possible theory, belief, viewpoint, or guess and show how each is related to every other. The words and lexical patterns of natural languages are not formalized as part of the theories in the lattice. Instead, they are used as indexing terms and patterns of terms for classifying and finding the relevant theories. Figure 5 shows the relationships.
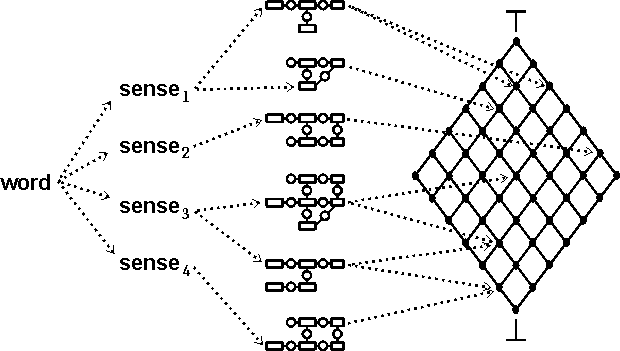
Figure 5: words → senses → canonical graphs → theories
The dotted arrows in Figure 5 represent pointers in computer storage, which are used to link the words of natural languages to chunks of knowledge that may be expressed in terms of those words. Instead of floating freely in the soup of Figure 4, each of those chunks is represented by a node in the lattice on the right of Figure 5. Those chunks could be arbitrarily large theories, or they could be parts of theories as small as a single proposition. No matter what its size, each chunk is called a theory, and its position in the lattice shows how it is related to every other theory. If theory X is above theory Y, then X is more general than Y, and Y is more specialized than X. If theory X is neither above nor below Y, then they are siblings or cousins; the lowest node above both of them is called their supremum, and the highest node below both of them is called their infimum (Sowa 2000). Each proposition in a theory is called an axiom, and it may be represented in a conceptual graph or in any notation that could be translated to CGs — which includes most versions of logic. Following are the four kinds of entities shown in Figure 5:
Figure 6 shows four basic ways of moving through the lattice from one theory to another: contraction, expansion, revision, and analogy. Each move corresponds to one of the four operators for theory revision. The first three operators were defined by the AGM axioms (Alchourrón et al. 1985); the fourth operator, which uses analogy to rename the labels of types and relations, was defined by Sowa (2000).
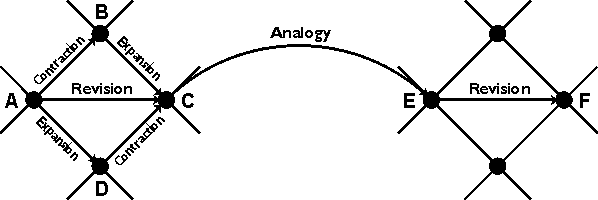
Figure 6: Four theory-revision operators
To illustrate the moves through the lattice, suppose that theory A is Newton's theory of gravitation applied to the earth revolving around the sun and that F is Niels Bohr's theory about an electron revolving around the nucleus of a hydrogen atom. The path from A to F is a step-by-step transformation of the old theory to the new one. The revision step from A to C replaces the gravitational attraction between the earth and the sun with the electrical attraction between the electron and the proton. That step can be carried out in two intermediate steps:
By repeated application of the four operators in Figure 6,
any theory or collection of beliefs can be converted into any other.
Multiple contractions would reduce a theory to the empty
or universal theory  at the top
of the lattice, which contains only the tautologies that are true of
everything. Multiple expansions would lead to the inconsistent
or absurd theory
at the top
of the lattice, which contains only the tautologies that are true of
everything. Multiple expansions would lead to the inconsistent
or absurd theory  at the
bottom of the lattice, which contains all axioms and is true of nothing.
The analogy operator allows short cuts that can jump across the lattice
by a systematic relabeling of the types and relations.
If the original theory is consistent, the analogy must also be consistent,
since the axioms are identical except for a change of names.
at the
bottom of the lattice, which contains all axioms and is true of nothing.
The analogy operator allows short cuts that can jump across the lattice
by a systematic relabeling of the types and relations.
If the original theory is consistent, the analogy must also be consistent,
since the axioms are identical except for a change of names.
The canonical graphs are derived from lexical resources such as WordNet or collections of information from dictionaries, encyclopedias, and corpora of texts. These graphs show the shallow semantic relationships that link the words and phrases of natural languages. As an example, Figure 7 shows a canonical graph for the concept type Give.

Figure 7: A canonical graph for the concept type Give
Figure 7 shows that the concept type Give typically has an animate agent (Agnt), an animate recipient (Rcpt), and an arbitrary entity as theme (Thme). The conceptual relations shown in Figure 7 are also called case relations or thematic roles in linguistics. The kind of information shown in canonical graphs is sometimes represented in frame notation, but the more general CG notation can use the full expressive power of logic in canonical graphs.
The canonical graph shown in Figure 7 was not derived from WordNet because WordNet does not yet show case relations, such as Agnt, Rcpt, and Thme. Among the users who have found a need for such information, Harabagiu and Moldovan (1998) observed "Perhaps one of the most useful additions to WordNet would be case relations associated with verbs. As discussed earlier, case constraints play an important role in the inference process." To remedy that lack, the IBM Corporation has donated a verb ontology to the public domain, under the care of CSLI. That ontology was prepared at IBM's expense by CSLI using the labels for case relations specified by Sowa (2000, Section B.4). Majumdar is using the IBM Verb Ontology to derive case relations for all the verbs classifed by Levin (1993); the results will then be combined with WordNet's information for the same verbs and be translated to CGs.
The TOSI approach is an adaptation of the knowledge-soup framework
that allows practical applications to be implemented
with a small lattice consisting of just a few closely related theories.
Figure 8 shows a special case of Figure 6 with just one theory:

Figure 8: words → word senses → canonical graphs → theory
The two kinds of knowledge illustrated in Figures 6 and 8 serve very different purposes, and they are organized in very different ways. The lexical knowledge encoded in words, word senses, and canonical graphs provides broad coverage, but it is not detailed enough for any specific task. The task-oriented knowledge, which may be encoded in axioms or in executable programs, is much more specific, much more precise, and much more fragile. Errors in the task-oriented knowledge cause bugs, which plague every programmer, and they become more numerous and more troublesome as the amount of knowledge becomes larger. Errors in the lexical knowledge, however, are less troublesome, they are often self-correcting, and they become less significant as more knowledge is added. The reason for the difference is illustrated by the two arrows labeled abduction and deduction in Figure 4:
To generate a conceptual graph that represents an interpretation, the Intellitex parser matches the pattern of concept types indicated by the word senses in the input sentence to the canonical graphs indexed by those types. The process of matching, which is called graph unification, generates a CG that is a common specialization of the input sentence and the canonical graphs. It is more specialized because it may contain background information that was implicit, but not actually stated in the input. In effect, the words of the input sentence determine one or more paths through the collection of canonical graphs derived from the lexical resources. The process of interpreting a sentence by following paths through a network of lexical information was pioneered by Ceccato (1961, 1964) in an early system for machine translation. Quillian (1966) used a version of path following for finding word associations through a network of dictionary definitions. More recently, versions of path following through the definitions and examples of WordNet have been widely used for semantic interpretation (Harabagiu & Moldovan 1998; Hirst & St-Onge 1998).
Since the words of a sentence may lead to different paths for different senses of the same word, some measure of relevance or likelihood is necessary to select the most promising path to try first. Intellitex uses a measure of evidence based on Bayesian statistics, with the prior probabilities for the Bayes equation estimated by a version of the Dempster-Shafer theory of evidence. The evidence for a particular interpretation depends on various features, such as the length of the path through the network and the density of interconnections in the graphs. The measure of evidence is used to evaluate different hypotheses in the abduction stage of Figure 4. The most likely interpretation is then used in the deduction stage to generate the desired answer or result of the task-oriented processing. If the first interpretation is found to be unsuitable for the deduction, then the next most likely interpretation can be chosen.
Analogy is the operation of finding similar patterns in different representations. It is both more primitive and more general than logical reasoning, and it is a fundmental operation used in every version of logic. Following is Peirce's classification of the three kinds of logical reasoning and the way analogy is used in each:
The VivoMind Analogy Engine (VAE), which was developed by Majumdar, is a high-performance analogy finder that uses conceptual graphs for the knowledge representation. It solves typical examples of analogy much faster than previous systems, and it has been used to process large amounts of data, some derived from English texts and the rest derived from computer data structures. An earlier system for finding analogies, called the Structure Mapping Engine (SME), requires time proportional to N3, where N is the number of relations in the current knowledge base or context to be searched (Forbus et al. 1995). A later version called MAC/FAC reduced the time by using a search engine to extract the most likely data before using SME to find analogies (Forbus et al. 2002). VAE, however, can find the same analogies in time proportional to (N log N). VAE can find analogies in the entire WordNet knowledge base in just a few seconds, even though WordNet contains over 105 relations. For that size, one second with an (N log N) algorithm would correspond to 30 years with an N3 algorithm.
VAE can process CGs from any source: natural languages, programming languages, and any kind of information that can be represented in graphs, such as organic molecules or electric-power grids. In an application to distributed interacting agents, VAE processes English messages and signals from sensors that monitor the environment. To determine an agent's actions, VAE searches for analogies to what humans did in response to similar patterns of messages and signals. To find analogies, VAE uses three methods of comparison, which can be used separately or together:
| Analogy of Cat to Car | |
|---|---|
| Cat | Car |
| head | hood |
| eye | headlight |
| cornea | glass plate |
| mouth | fuel cap |
| stomach | fuel tank |
| bowel | combustion chamber |
| anus | exhaust pipe |
| skeleton | chasis |
| heart | engine |
| paw | wheel |
| fur | paint |
As this table illustrates, there is an enormous amount of background knowledge stored in lexical resources such as WordNet. It is not organized in a form that is precise enough for deduction, but it is adequate for the more primitive method of analogy. Since there are many possible paths through all the definitions and examples of WordNet, most comparisons generate multiple analogies, which are evaluated by the same kind of Bayesian statistics used to measure the evidence for different semantic interpretations of an input sentence. The analogy shown in the above table received a high score because VAE found many matching labels and subgraphs in corresponding parts of a cat and parts of a car:
As the cat-car comparison illustrates, analogy is a versatile method for using informal, unstructured background knowledge. But analogies are also valuable for comparing the highly formalized knowledge of one axiomatized theory to another. In the process of theory revision, Niels Bohr used an analogy between gravitational force and electrical force to derive a theory of the hydrogen atom as analogous to the earth revolving around the sun. The third method of analogy, which finds matching transformations, can also be used to determine the precise mappings required for transforming one theory or representation into another. As an example, Figure 9 shows a physical structure that could be represented by many different data structures.

Figure 9: A physical structure to be represented by data
Programmers who use different tools, databases, or programming languages often use different, but analogous representations for the same kinds of information. LISP programmers, for example, prefer to use lists, while FORTRAN programmers prefer vectors. Conceptual graphs are a highly general representation, which can represent any kind of data stored in a digital computer, but the types of concepts and relations usually reflect the choices made by the original programmer, which in turn reflect the options available in the original programming tools. Figure 10 shows a representation for Figure 9 that illustrates the typical choices used with relational databases.

Figure 10: Two structures represented in a relational datbase
On the left of Figure 10 are two structures: a copy of Figure 9 and an arch constructed from three blocks. On the right are two tables: the one labeled Objects lists the identifiers of all the objects in both tables with their shapes and colors; the one labeled Supports lists each object that supports (labeled Supporter) and the object supported (labeled Supportee). As Figure 10 illustrates, a relational database typically scatters the information about a single object or structure of objects into multiple tables. For the structure of pyramids and blocks, each object is listed once in the Objects table, and one or more times in either or both columns of the Supports table. Furthermore, information about the two disconnected structures shown on the left is intermixed in both tables. When all the information about the structure at the top left is extracted from both tables of Figure 10, it can be mapped to the conceptual graph of Figure 11.

Figure 11: A CG derived from the relational DB
In Figure 11, each row of the table labeled Objects is represented by a conceptual relation labeled Objects, and each row of the table labeled Supports is represented by a conceptual relation labeled Supports. The type labels of the concepts are mostly derived from the labels on the columns of the two tables in Figure 10. The only exception is the label Entity, which is used instead of ID. The reason for that exception is that the term ID is a metalevel term about the representation language; it is not a term that is derived from the entities in the domain of discourse. The concept [Entity: E], for example, says that E is an instance of type Entity. The concept [ID: "E"], however, would say that the character string "E" is an instance of type ID. The use of the label Entity instead of ID avoids mixing the metalevel with the object level. Such mixing of levels is common in most programs, since the computer ignores any meaning that might be associated with the labels. In logic, however, the fine distinctions are important, and CGs mark them consistently.
When natural languages are translated to CGs, the distinctions must be enforced by the semantic interpreter. Figure 12 shows a CG that represents the English sentence, A red pyramid A, a green pyramid B, and a yellow pyramid C support a blue block D, which supports an orange pyramid E. The conceptual relations labeled Thme and Inst represent the case relations theme and instrument. The relations labeled Attr represent the attribute relation between a concept of some entity and a concept of some attribute of that entity. The type labels of concepts are usually derived from nouns, verbs, adjectives, and adverbs in English.
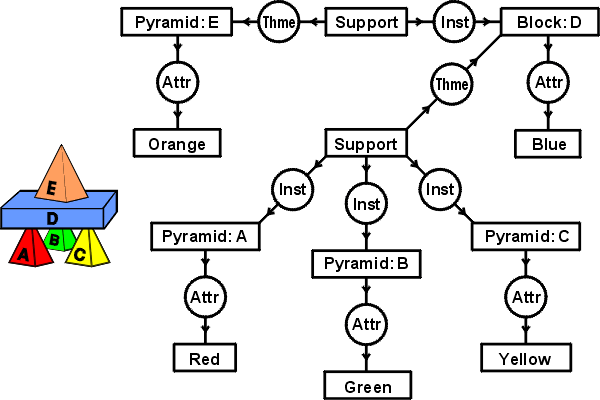
Figure 12: A CG derived from an English sentence
Although the two conceptual graphs represent equivalent information, they look very different. In Figure 11, the CG derived from the relational database has 15 concept nodes and 9 relation nodes. In Figure 12, the CG derived from English has 12 concept nodes and 11 relation nodes. Furthermore, no type label on any node in Figure 11 is identical to any type label on any node in Figure 12. Even though some character strings are similar, their positions in the graphs cause them to be treated as distinct. In Figure 11, orange is the name of an instance of type Color; and in Figure 12, Orange is the label of a concept type. In Figure 11, Supports is the label of a relation typen; and in Figure 12, Support is not only the label of a concept type, it also lacks the final S.
Because of these differences, the strict method of unification could not show that the graphs are identical or even related. Even the more relaxed methods of matching labels or matching subgraphs are unable to show that the two graphs are analogous. The third method of analogy, however, can find matching transformations that can translate Figure 11 into Figure 12 or vice-versa. When VAE was asked to compare those two graphs, it found the two transformations shown in Figure 13. Each transformation determines a mapping between a type of subgraph in Figure 11 and another type of subgraph in Figure 12.

Figure 13: Two transformations discovered by VAE
The two transformations shown in Figure 13 define a version of graph grammar for parsing one kind of graph and mapping it to the other. The transformation at the top of Figure 13 can be applied to the five subgraphs containing the relations of type Objects in Figure 11 and relate them to the five subgraphs containing the relations of type Attr in Figure 12. That same transformation could be applied in reverse to relate the five subgraphs of Figure 12 to the five subgraphs of Figure 11. The transformation at the bottom of Figure 13 could be applied from right to left in order to map Figure 12 to Figure 11. When applied in that direction, it would map three different subgraphs, which happen to contain three common nodes: the subgraph extending from [Pyramid: A] to [Block: D]; the one from [Pyramid: B] to [Block: D]; and the one from [Pyramid: C] to [Block: D]. When applied in the reverse direction, it would map three subgraphs of Figure 11 that contained only one common node.
The transformations shown in Figure 13 would have a high measure of evidence because they are used repeatedly in exactly the same way. A single transformation of one subgraph to another subgraph with no matching labels would not contribute anything to the weight of evidence. But if the same transformation is applied twice, then its likelihood is greatly increased. Transformations that can be applied three times or five times to relate all the nodes of one graph to all the nodes of another graph have a likelihood that comes close to being a certainty.
Of the three methods of analogy used in VAE, the first two — matching labels and matching subgraphs — are also used in the Structure Mapping Engine (SME), but VAE can find the same analogies in time proportional to (N log N), where N is the number of relations in the current knowledge base or some excerpt from the knowledge base. The third method of matching transformations, which only VAE is capable of performing, is more complex because it depends on analogies of analogies. Unlike the first two methods, which VAE can apply to very large knowledge bases, the third method takes polynomial time, and it can only be applied to much smaller amounts of data. In practice, the third method is usually applied to small parts of an analogy in which most of the mapping is done by the first two methods and only a small residue of unmatched nodes remains to be mapped. In such cases, the number N is small, and the mapping can be done quickly. Even for mapping Figure 11 (with N=9) to Figure 12 (with N=11), the third method took a few seconds, whereas the time for methods one and two on graphs of such size would be less than a millisecond.
Each of the three methods of analogy determines a mapping of one CG to another. The first two methods determine a node-by-node mapping of CGs, where some or all of the nodes of the first CG may have different type labels from the corresponding nodes of the other. The third method determines a more complex mapping, which comprises multiple mappings of subgraphs of one CG to subgraphs of the other. These methods can be applied to CGs derived from any source, including natural language texts or computer language implementations. The next section describes the use of analogies to compare CGs derived from English documentation to CGs derived from programming languages. As a result of the comparison, VAE was able to discover discrepancies between the English specifications and the computer implementations.
Errors and misunderstandings are inevitable in human communication, and the seriousness of the errors escalates when computers are involved. Although computers have reduced or eliminated errors in storing and transmitting data, the most serious errors are caused by differences in terminology, conventions, formats, and database organization. Even when the formats and terminology are identical, different people who enter data may have different views about how to translate natural language words and phrases into the computer notations. Since Intellitex can map both natural languages and computer languages to the same CG notation, it can call upon VAE to search for matches and mismatches between the documentation and the implementation. This kind of checking is important for any application, but it is especially critical when the programs, data, and documentation have been accumulating over long periods of time.
A major application for Intellitex was the legacy reengineering of the programs and documentation of a large corporation, which had programs in daily use that were up to forty years old. The programmers who wrote them and the managers who ordered them were long since gone, but the programs continued to run. The English documentation specified how the programs were supposed to work, but nobody knew what errors, discrepancies, and obsolete business procedures might be buried in the code. The task required an analysis of 100 megabytes of English documentation, 1.5 million lines of COBOL programs, and several hundred control-language scripts, which called the programs and specified the data files and formats. Over time, the English terminology, computer formats, and file names had changed. Some of the format changes were caused by new computer systems and business practices, and others were required by different versions of federal regulations.
The task was to reverse-engineer the business procedures from the source code, to detect discrepancies between the programs and the documentation, and to specify a data warehouse that would unify all the company's information. The results were to be presented as
The entire task was finished in eight weeks by two programmers, Majumdar and André LeClerc, with the aid of an earlier version of Intellitex and the analogy engine. Before running Intellitex, they spent three weeks on the project design and analysis, writing programs to access 300 computers scattered across North America, and writing grammars to parse the COBOL data and environment divisions and the IBM Job Control Language (JCL). Then they ran Intellitex for three weeks — running 24 hours a day, seven days a week on a 750 MHz Pentium III computer. Finally they translated the results to the desired formats and stored them on one CD-ROM.
While Intellitex was running, it used grammars for three different languages, English, COBOL, and JCL. For the semantic interpretation of English, it used WordNet supplemented with canonical graphs specialized for the application. Only three simple canonical graphs were used for the concept type Process and any of its subtypes:
[Process]→(Uses)→[Data]. [Process]→(Generates)→[Data]. [Process]→(Modifies)→[Data].New concept types were added to the hierarchy to specify various subtypes, such as CobolProcess, JCLProcess, and HumanProcess as well as all the data and file structures recognized by COBOL and JCL. For the semantic interpretation of COBOL and JCL, Intellitex did not need the canonical graphs derived from WordNet, but it used the same task-oriented canonical graphs and concept types. For all three languages, Intellitex saved only the information that matched the task-oriented graphs; everything else was ignored. That is the fundamental TOSI principle: everything is parsed syntactically, but only the task-oriented information is processed semantically.
While Intellitex was processing the programs and documentation, it called upon the analogy engine to compare the graphs extracted from different programs or English texts. For each comparison, VAE generated a weight of evidence that measured its confidence in the results. In the great majority of cases, the evidence was strong enough that no human confirmation was needed. But if the evidence was weak, VAE posted a notice for Majumdar or LeClerc to confirm or correct. Sometimes those notices indicated program bugs, errors in the documentation, or vague specifications that were interpreted in different ways by different programmers.
At one point in the analysis, VAE discovered an anlogy for which the evidence was weak because it violated a constraint. According to the type hierarchy, every employee is a human being, and no human being is a computer. But according to the COBOL programs, it was permissible for some employees to be computers. At first, Majumdar and LeClerc were concerned that Intellitex might have made a mistake, but on further investigation, they discovered two employees in the database that were actually computers. Apparently, a COBOL programmer had made a quick patch in 1979:
VAE also discovered ambiguous, conflicting, and sometimes redundant paths through the corporate database. Figure 14 shows three concepts that are directly linked to geographical location: ClientHQ, BusinessUnit, and Employee. An employee's location could be found by a direct link, or it could be derived by following a path from the employee to the business unit and then to the location of the business unit. Since those two locations should be the same, the data would be redundant. To determine the location of a market, there are two possible paths from Market to Location. The English documentation said that the market location was determined by the location of of the business unit. But the COBOL programs that generated market reports followed the path from Market to ClientHQ to Location. As a result, management had for many years been using erroneous data as a basis for marketing decisions.

Figure 14: Ambiguous paths through the database
As these examples illustrate, the Intellitex parser and semantic interpreter can process natural languages as well as computer-oriented languages. Each language requires a different grammar, but they can all use the same canonical graphs for generating CGs that represent the meaning. After the source languages have been translated to CGs, the analogy engine can be used to compare graphs derived from different sources and find matches or mismatches. When the graphs match, a TOSI program written for the particular task puts the English descriptions in the glossary and puts the COBOL or JCL specifications in the data dictionary. If the graphs do not match, the TOSI program posts a notification, which some human expert can investigate further.
Although this example deals with computer systems, similar techniques can be applied to any subject. For bioinformatics, TOSI can be used to relate information extracted from published papers to information stored in databases. The next section shows how Intellitex was able to analyze abstracts from papers on molecular biology in order to derive canonical graphs.
The canonical graphs used by Intellitex have been derived by translating other lexical resources into CGs. For specialized applications, new canonical graphs are necessary to show the conventions, terminology, abbreviations, and patterns of relations that are familiar to the people who use the applications. Bioinformatics, for example, has an enormous vocabulary of terms from chemistry, biology, medicine, and computer science that do not appear in general-purpose dictionaries. To illustrate the language, the following abstract of a paper by Volles and Lansbury (2002) shows a text that might be processed for bioinformatics:
Two mutations in the protein alpha-synuclein (A30P and A53T) are linked to an autosomal dominant form of Parkinson's disease. Both mutations accelerate the formation of prefibrillar oligomers (protofibrils) in vitro, but the mechanism by which they promote toxicity is unknown. Protofibrils of wild-type alpha-synuclein bind and permeabilize acidic phospholipid vesicles. This study examines the relative membrane permeabilizing activities of the wild type, mutant, and mouse variants of protofibrillar alpha-synuclein and the mechanism of membrane permeabilization. Protofibrillar A30P, A53T, and mouse variants were each found to have greater permeabilizing activities per mole than the wild-type protein. The leakage of vesicular contents induced by protofibrillar alpha-synuclein exhibits a strong preference for low-molecular mass molecules, suggesting a pore-like mechanism for permeabilization. Under conditions in which the vesicular membrane is less stable (lack of calcium as a phospholipid counterion), protofibril permeabilization is less size-selective and monomeric alpha-synuclein can permeabilize via a detergent-like mechanism. We conclude that the pathogenesis of Parkinson's disease may involve membrane permeabilization by protofibrillar alpha-synuclein, the extent of which will be strongly dependent on the in vivo conditions.
This paragraph uses many terms that do not occur in WordNet and other common lexical resources. It also introduces special names of proteins, A30P and A53T, and it uses parenthetical expressions, whose grammatical relationships to the sentences in which they occur are not defined by ordinary English grammar. Furthermore, the people who use those terms seldom have the training in logic and linguistics necessary for writing formal definitions. Therefore, tools are needed to generate canonical graphs automatically from text or semiautomatically by means of a dialog between a computer and a domain expert who has no training in how to draw or read such graphs.
When presented with a text that uses completely new vocabulary, Intellitex can generate a tentative semantic interpretation by using abduction to hypothesize new concept types and then generating type labels from the words and phrases in the text. To predict where a newly generated concept type would fit in the hierarchy, Intellitex uses the analogy methods of VAE to compare the CG surrounding the new type to other CGs derived from the same text or to CGs derived from WordNet and other lexical resources. The least common supertype of the analogous concept types (called its supremum) may be assumed as the supertype of the new concept type. If a new concept type occurs more than once, or if it has multiple interconnections to other nodes in the CG, the weight of evidence for the predicted position in the type hierarchy increases. Following are the concept types that were the most densely interconnected and therefore considered to be the most significant for this text; each one is followed by its predicted supertype.
These are indeed key concepts for understanding the text. The protein alpha-synuclein is the focus of the study, and the basic question is which of the two kinds of mechanisms, detergent-like or pore-like, is involved. The two concepts SizeSelective and LowMolecular are necessary for determining that a pore-like mechanism is involved. (personal communication)The key concepts in the above list were not selected because of their frequency of occurrence in the text, but because they occurred in parts of the conceptual graph that were the most densely interconnected. In many cases, frequency and density are unrelated: the concept AlphaSynuclein occurs six times in the paragraph, but DetergentLikeMechanism and PoreLikeMechanism each occur only once. In addition to finding significant concept types, Intellitex derives CGs that show how they are related to one another. Those CGs can be considered as candidates for the canonical graphs of other texts on the same subject. For confirmation or correction by a domain expert, the CGs can be displayed as graphs or be translated back to English and other natural languages. Conceptual graphs have been used as a language-independent representation for medical information: the RÉCIT system extracts knowledge from documents written in English, French, or German and answers questions in any of the three languages (Rassinoux et al. 1998).
Intellitex derived the CGs for the above paragraph by using only the general lexical knowledge stored in WordNet. It did not use any of the lexicons, word lists, or databases designed for bioinformatics. Such information would be valuable for tailoring the lexical resources for such topics. But even without such knowledge, Intellitex was able to extract significant concepts from short abstracts. This approach should be distinguished from statistical methods, such as latent semantic analysis (LSA), which require a large training corpus in order to construct a semantic space for a particular subject. To analyze technical material, "the LSA space was based on the 30,047 encyclopedia articles from Grolier's encyclopedia" (Foltz et al. 1998). For a specialized topic, it was based on "24 Grolier's articles related to the heart and heart disease." LSA and related methods are important for many applications, such as finding relevant documents. But a parser and semantic interpreter like Intellitex is necessary to derive the significant concepts from a text of any size, organize them in a type hierarchy, and show the patterns of relations in which they occur.
A simple parser can discover many relations that are beyond the scope of statistical techniques, but a semantic interpreter is necessary for more detailed analysis. For special cases, however, a highly simplified analyzer may be adequate for information extraction, as Blaschke et al. (1999) observed:
We describe the design of a system for automatic detection of protein-protein interactions from scientific text. The basic idea is that sentences derived from sets of abstracts will contain a significant number of protein names connected by verbs that indicate the type of relation between them. By prespecifying a limited number of possible verbs, we avoid the complexity of semantic analysis.Their analyzer depends heavily on the specialized syntax and terminology of abstracts about topics in molecular biology. They limit the semantics to a long list of protein names linked by 14 verbs or their nominalized forms, such as activate-activation or inhibit-inhibition. Their syntax is limited to the pattern protein verb protein, and they ignore less common patterns of the form protein protein verb or verb protein protein. The authors are willing to accept occasional errors in the analysis of any particular abstract because they are most interested in finding repeated occurrences in a collection of 111,747 abstracts. The conclusion of the paper illustrates the similarities and differences between their approach and Intellitex:
To summarize, the three main results of this work are: first, restricting the number of relevant names and verbs virtually eliminates the problem of text understanding; second, specifying a particular subproblem enhances quality and accuracy of the results obtained from free text (here we dealt with small problems of protein-protein interactions in specific Drosophila systems) and finally the repeated occurrence of certain facts can enhance the quality of the discovery and strengthen the identification of particular relationships.These three observations are compatible with the TOSI approach of restricting detailed semantic interpretation to a specific task. But when a sentence is relevant to the task, Intellitex does a more thorough syntactic and semantic analysis. The only task-oriented canonical graph needed for this application is
[Protein]←(Inst)←[Act]→(Thme)→[Protein].A more detailed parser could recognize this pattern in all its syntactic variations and distinguish the phrase protein-1's inhibition of protein-2 from protein-1's inhibition by protein-2. A semantic interpreter could also detect negations even when they are implicit in words such as deny or exclude. The greater accuracy of the TOSI approach is necessary when the amount of data is too small to tolerate a significant number of errors. TOSI also supports greater flexibility by accommodating multiple canonical graphs for the same task, or even for two or more related tasks.
For new applications, two kinds of knowledge must be added to the soup: new lexical knowledge for interpreting texts and new theories for task-oriented reasoning about the application. Lexical knowledge can be derived from natural language texts; formal theories, however, cannot be derived automatically. As Perlis (1982) observed, "It is not possible to translate informal specifications to formal specifications by any formal algorithm." New theories in the lattice or new programs that perform equivalent computation will still require human assistance: they must be written by programmers or by experts in the subject matter who use computer-aided tools for converting their knowledge into a computable form.
The authors are working on the design and development of such tools, but they are not yet finished. As examples of similar tools, Skuce and his colleagues (1995, 1998, 2000) have designed an evolving series of systems for knowledge extraction (KE), which use an English-like language called ClearTalk. Although ClearTalk is valuable for communicating with people, its power is limited by the frame-like internal representation used in the KE tools. By using Intellitex to analyze source texts and CGs as the internal representation, the power of the KE tools would be enormously increased: more of the knowledge extraction process could be automated, the expressive range of ClearTalk could cover full first-order logic with modal and metalevel extensions, and for greater readability, any knowledge encoded in rules, theories, or canonical graphs could be translated to natural language.
The technology presented in this paper has been used in commercial applications, but there are still many research problems to be addressed. An important advantage of TOSI is the flexible framework, which allows current technology to be applied to practical problems without preventing ongoing research projects from adding new theories to the lattice even while it is in active use. This flexibility should be contrasted with four other common approaches in artificial intelligence:
The knowledge-soup framework, as implemented in Intellitex, can accommodate all four approaches. Sowa (1999) observed that the templates used by shallow parsers for information extraction were special cases of the canonical graphs used in CG-based systems. Furthermore, the canonical formation rules, which are used to link those graphs together, can be used to support Peirce's rules of inference for logical reasoning. Consequently, the four approaches can be viewed as related aspects of a continuum:
The full lattice of knowledge soup has not yet been implemented, but it represents a goal toward which further research and development is heading. The current Intellitex implementation uses the TOSI approach to support just a few theories at a time. To derive new theories dynamically, VAE has been used to implement theory revision for an application with multiple interacting agents: as an agent's environment changes, analogies are used to derive new axioms, to select axioms from the knowledge soup, or to determine which of the current axioms are no longer appropriate. The knowledge-soup framework and the TOSI special case provide the flexibility to accommodate current practice in AI and to support a wide range of research and development for the future. There are still many open research issues in both natural language semantics and in AI methods of reasoning, but the framework provides a way of implementing practical applications while the research is continuing.
Alchourrón, C., P. Gärdenfors, & D. Makinson (1985) "On the logic of theory change: partial meet contraction and revision functions," Journal of Symbolic Logic 50:2, 510-530.
Blaschke, C., M. A. Andrade, C. Ouzounis, & A. Valencia (1999) "Automatic extraction of biological information from scientific text: protein-protein interactions," Proc. of AAAI Conference on Intelligent Systems for Molecular Biology, pp. 60-67.
Ceccato, Silvio (1961) Linguistic Analysis and Programming for Mechanical Translation, Gordon and Breach, New York.
Ceccato, Silvio (1964) "Automatic translation of languages," Information Storage and Retrieval 2:3, 105-158.
Chomsky, N. (1957) Syntactic Structures, Mouton, The Hague.
Esch, J., & R. A. Levinson (1995) "An Implementation Model for Contexts and Negation in Conceptual Graphs", in G. Ellis, R. A. Levinson, & W. Rich, eds., Conceptual Structures: Applications, Implementation, and Theory, Lecture Notes in AI 954, Springer-Verlag, Berlin, pp. 247-262.
Esch, J., & R. A. Levinson (1996) "Propagating Truth and Detecting Contradiction in Conceptual Graph Databases," in P. W. Eklund, G. Ellis, & G. Mann, eds.,
Fellbaum, C., ed. (1998) WordNet: An Electronic Lexical Database, MIT Press, Cambridge, MA.
Foltz, P. W., W. Kintsch, & T. K. Landauer (1998) "The measurement of textual coherence with latent semantic analysis," Discourse Processes 25:2-3, 285-307.
Forbus, K. D., D. Gentner, & K. Law (1995) "MAC/FAC: A Model of Similarity-Based Retrieval," Cognitive Science 19:2, 141-205.
Forbus, K. D., T. Mostek, & R. Ferguson (2002) "An analogy ontology for integrating analogical processing and first-principles reasoning," Proceedings of IAAI-02 pp. 878-885.
Grice, H. P. (1975) "Logic and conversation," in P. Cole & J. Morgan, eds., Syntax and Semantics 3: Speech Acts, Academic Press, New York, pp. 41-58.
Harabagiu, S. M., & D. I. Moldovan (1998) "Knowledge processing on an extended WordNet," in Fellbaum (1998) pp. 379-405.
Hirst, G., & D. St-Onge (1998) "Lexical chains as representations of context for the detection and correction of malapropisms," in Fellbaum (1998) pp. 305-351.
Hobbs, J. R., M. Stickel, D. Appelt, & P. Martin (1993) "Interpretation as abduction," Artificial Intelligence, vol. 63, no. 1-2, pp. 69-142.
Hobbs, J. R., D. Appelt, J. Bear, D. Israel, M. Kameyama, M. Stickel, & M. Tyson (1997) "FASTUS: A cascaded finite-state transducer for extracting information from natural-language text," in E. Roche & Y. Schabes, eds., Finite-State Language Processing, MIT Press, Cambridge, MA, pp. 383-406.
Kamp, H., & U. Reyle (1993) From Discourse to Logic, Kluwer, Dordrecht.
Lenat, D. B. (1995) "CYC: A large-scale investment in knowledge infrastructure," Communications of the ACM 38:11, 33-38.
Lenat, D. B., & R. V. Guha (1990) Building Large Knowledge-Based Systems, Addison-Wesley, Reading, MA.
Levin, B. (1993) English Verb Classes and Alternations, University of Chicago Press, Chicago.
Levinson, R. A. (1996) "General game-playing and reinforcement learning," Computational Intelligence 12:1, 155-176.
Levinson, R. A., & G.\Ellis (1992) "Multilevel hierarchical retrieval," Knowledge Based Systems 5:3, 233-244.
Miller, G. A. (1995) "WordNet: A lexical database for English," Communications of the ACM 38:11, 39-41.
Peirce, C. S. (1909) Manuscript 514, with commentary by J. F. Sowa, available at http://www.jfsowa.com/peirce/ms514.htm
Perlis, A. J. (1982) "Epigrams in Programming," SIGPLAN Notices, Sept. 1982, ACM. Available at http://www.cs.yale.edu/homes/perlis-alan/quotes.html
Quillian, M. R. (1966) Semantic Memory, abridged version in M. Minsky, ed., Semantic Information Processing, MIT Press, Cambridge, MA, 1968, pp. 227-270.
Rassinoux, A-M., R. H. Baud, C. Lovis, J. C. Wagner, J-R. Scherrer (1998) "Tuning up conceptual graph representation for multilingual natural language processing in medicine," in M-L Mugnier & M. Chein, eds., Conceptual Structures: Theory, Tools, and Applications, Lecture Notes in AI 1453, Springer-Verlag, Berlin, pp. 390-397
Skuce, D., & T. Lethbridge (1995) "CODE4: A unified system for managing conceptual knowledge," International J. of Human-Computer Studies, 42 413-451.
Skuce, D. (1998) "Intelligent knowledge management: integrating documents, knowledge bases, and linguistic knowledge," in Proceedings of KAW'98, Calgary.
Skuce, D. (2000) "Integrating web-based documents, shared knowledge bases, and information retrieval for user help," Computational Intelligence 16:1.
Sowa, J. F. (1984) Conceptual Structures: Information Processing in Mind and Machine, Addison-Wesley, Reading, MA.
Sowa, J. F. (1990) "Crystallizing theories out of knowledge soup," in Z. W. Ras & M. Zemankova, eds., Intelligent Systems: State of the Art and Future Directions, Ellis Horwood Ltd., London, pp. 456-487.
Sowa, J. F. (1999) "Relating templates to logic and language," in Information Extraction: Towards Scalable, Adaptable Systems, ed. by M. T. Pazienza, Lecture Notes in AI #1714, Springer-Verlag, pp. 76-94.
Sowa, J. F. (2000) Knowledge Representation: Logical, Philosophical, and Computational Foundations, Brooks/Cole Publishing Co., Pacific Grove, CA.
Stewart, J. (1996) Theorem Proving Using Existential Graphs, MS Thesis, Computer and Information Science, University of California at Santa Cruz.
Volles, M. J., & P. T. Lansbury, Jr. (2002). "Vesicle permeabilization by protofibrillar alpha-synuclein is sensitive to Parkinson's disease-linked mutations and occurs by a pore-like mechanism." Biochemistry 41(14): 4595-602.
Yokoi, T. (1995) "The EDR electronic dictionary," Communications of the ACM 38:11, 42-44.