Negotiation Instead of Legislation
John F. Sowa
Abstract.
For years, the Holy Grail of IT has been a magical solution to the
problem of making incompatible systems interoperable. The most common
approach is to legislate some new kind of language, framework, schema,
vocabulary, terminology, nomenclature, ontology, or metadata. Whatever
it is called, the legislators promise that it will somehow convert the
knowledge cacophony of the World Wide Web into a knowledge symphony.
Yet for any given task, people manage to work together without
reorganizing the totality of all the knowledge soup in their heads.
Instead of legislation, they use negotiation to make the minimal
adjustments needed to get the job done. To make negotiation possible
among computer systems, several processes must be accomplished:
defining the task to be done, mapping the task-related concepts to the
available structures of each system, and making adjustments only when
necessary. This talk discusses the mechanisms of negotiation, analyzes
their implications for system design, and shows how they can enable
legacy systems to interoperate in dynamically changing environments.
These slides were prepared for a keynote presentation to be given at the
Knowledge
Technologies Conference on March 13, 2002, in Seattle, Washington.
Knowledge Soup
Fundamental problem:
- Information in people's heads is far too disorganized
to be called a knowledge base.
- But every computer program always does something very precise.
- Result is an inevitable mismatch:
Human Intentions ≠ Computer Implementations
Implementation1 ≠
Implementation2 ≠
Implementation3...
Standards ≠ Implementations
Legislation
Proposed solution: Edict a standard that every implementation
shall obey.
Limitations:
- Assumes an omniscient legislator.
- Requires an Info Czar with an army of enforcers.
- Cannot accommodate legacy systems.
- Cannot anticipate future developments.
Conceptual Schema

ANSI SPARC, 1978.
ISO Standards Project, R.I.P. 1999.
Born again as the Semantic Web.
Negotiation
- Despite different languages, customs, and beliefs, people manage
to work together.
- But human collaboration varies from one task to another.
- Task-related local agreements are possible.
- But all attempts at global agreements
break down in religious wars.
Foundations for Interoperability
- Abandon all hope of global agreements.
- For any given task, find a common, localized basis for agreement.
- Map conflicting vocabulary to the common base.
- Negotiate a sub-ontology with the scope of that base
for the purpose of supporting the given task.
Questions
How can independently developed computer systems
- Negotiate?
- Find a basis for agreement?
- Map different vocabularies to a common base?
- Establish precise, unambiguous communication on a local task
without having a common global framework?
Answer
Use automated or semi-automated tools that can
- Determine the significant canonical graphs
— patterns of concepts and relations
that are central to the given task.
- Map the canonical graphs to the syntax and vocabulary
used by each of the systems that must interoperate.
- Analyze all available information with a shallow syntactic
and semantic parser.
- Use the canonical graphs to extend the shallow analysis
to a deeper semantic interpretation for those passages that mention
the significant concepts and relations.
- Negotiate revisions and adjustments only when different systems
use incompatible representations.
Implementing the Answer
The fundamental research as been done:
- Conceptual graphs (CGs) as a highly expressive version of logic
(FOL, HOL, and modal logic).
- Efficient CG algorithms for finding specializations,
generalizations, and analogies.
- Theory revision techniques.
Applied R & D to put it all together:
- Levinson-Ellis algorithms for specialization and generalization.
- Majumdar's algorithms for finding analogies.
- Task-oriented semantic interpretation (TOSI).
- Tarau's BinProlog + CGs + distributed agents.
Representing a Physical Structure

CG Derived from Relational DB

CG Derived from English
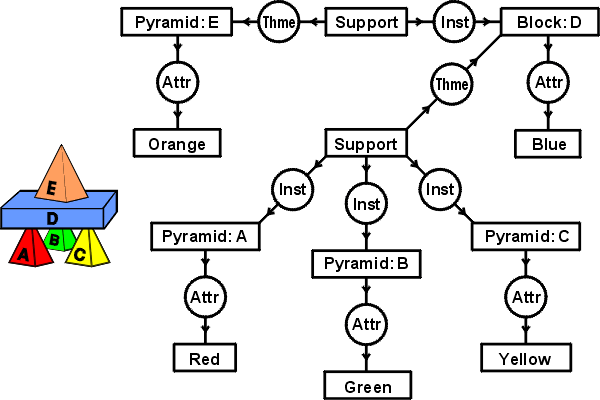
"A red pyramid A, a green pyramid B, and a yellow pyramid C
support a blue block D, which supports an orange pyramid E."
The Two CGs Look Very Different
- CG derived from the RDB has 15 concept nodes
and 8 relation nodes.
- CG derived from English has 12 concept nodes
and 11 relation nodes.
- No label on any node in the first graph is identical to any
label on any node in the second graph.
- But there are some structural similarities between the two graphs.
- Can a computer find them automatically?
Finding Analogies
- In natural languages, structural similarities
with different labels are called analogies and metaphors.
- Finding analogies and metaphors is the cornerstone of creativity
in every field:
- Ranging from scientific discoveries and patentable inventions
- To creating new jokes, art works, or culinary delights.
- Analogies are also important for finding common concepts
in different natural languages or even in the same language:
- "A red pyramid"
- "A pyramid-shaped object of color red"
- They are also important for finding common patterns and themes
in different programming languages:
- Java, LISP, APL, Prolog, C, FORTRAN, COBOL, SQL, JCL, and VB
VivoMind
A CG-based analogy finder developed by Arun Majumdar:
- Searches for structural similarities in conceptual graphs
— even though they may be expressed in different words or concepts.
- Solves all the published test cases of analogies.
- Processes CGs from any source:
-
Natural language text or speech
-
Programming languages or SQL databases
-
Graphs of any kind, such as organic molecules
or electrical power grids
Structural Mappings
VivoMind uses multiple algorithms to find analogies
at different levels of complexity:
- Matching labels:
- The simplest search begins at nodes that have identical labels.
- But this approach fails when the graphs to be compared have no
common labels.
- Matching subgraphs:
- The next algorithm searches for common subgraphs with possibly
different labels.
- This approach also fails when the only common subgraphs
are very small.
- Combining nodes:
- VivoMind's next algorithm tries to match larger combinations
of nodes in the two graphs to be compared.
- This approach successfully finds mappings of
each graph to and from the other.
Mappings Found by VivoMind

These mappings can be also be used to translate other graphs that
use the same two ontologies.
VivoMind for Legacy Re-engineering
Who:
- A company with 9000 employees.
- Several hundred programmers.
- 2500 data-entry clerks.
What:
- 300 legacy computer systems of 77 different types.
- 1.5 million lines of COBOL (up to 40 years old).
- Several hundred JCL scripts.
- 100 megabytes of documentation (up to 40 years old)
— text files (in EBCDIC and ASCII), e-mails, Lotus Notes, HTML,
and some oral communications.
- Changing terminology over the years
— with changing data formats for different versions of Federal regulations.
- 8 PCs with text files that are edited by hand before going
to the mainframes.
- All systems connected in a TCP/IP network.
Requirements
- Reverse engineer the business procedures from the source code.
- Specify a data warehouse to unify all the company's information.
- Produce a data architecture in the form of
- Glossary of company terminology (relating different versions over
the past 40 years)
- Data dictionary of all files, data elements, and data types,
with all versions of the names of the processes and the data they
use, generate, or modify.
- Yourdon-DeMarco data flow diagrams
- Physical process architecture diagrams
- System context diagrams
Study Project
- A major consulting company estimated
- Ed Yourdon signed a contract for a study project
- Two programmers: Arun Majumdar and André LeClerc
- Six weeks
Results
Much more than a study — they finished everything
in 6 weeks.
- Three weeks for customization:
- Design and logistics done by Majumdar and LeClerc
- Extensions to VivoMind written by Majumdar
- Three weeks to run VivoMind + extensions
— 24 hours a day on a 750 MHz Pentium III.
- Produced one CD-ROM with integrated views of everything:
Glossary, data dictionary, data flow diagrams, process architecture,
system context diagrams.
Canonical Graphs
Same task-oriented canonical graphs for interpreting the semantics
of English, COBOL, and JCL:
[Process]->(Uses)->[Data]
[Process]->(Generates)->[Data]
[Process]->(Modifies)->[Data]
With subtypes for all the kinds of processes and data,
including files and records, of COBOL and JCL.
Task-Oriented Semantic Interpreter
Broad-coverage syntax and semantics:
- Large lexicon based on WordNet supplemented with other resources.
- But shallow semantic coverage.
- Too much irrelevant information.
- Not detailed enough for any specific task.
TOSI supplements the lexicon with canonical graphs
for the specific task:
- Broad, but shallow parsing for everything.
- Deeper analysis for the items of interest.
- Same techniques applied to English, COBOL, and JCL
— different syntax, but same canonical graphs.
Conclusions
Conceptual graphs represent
- Shallow semantics for broad coverage.
- Deeper semantics for items of interest.
- Full power of logic for deduction, induction, and abduction.
CG tools support
- Specialization, generalization, and analogy.
- Associative search and precise deduction.
- Fast parsing and deeper analysis.
Together, the theory and the tools enable negotiated agreements
instead of legislated edicts.
For Further Reading
A textbook on knowledge representation that covers all the above topics:
A guided tour
of ontology, conceptual structures, and logic:
-
http://www.jfsowa.com/ontology/guided.htm
An article
about the templates used for information extraction, their use
in shallow parsing, and their relationship to conceptual graphs:
-
http://www.jfsowa.com/pubs/template.htm
A philosophical
analysis of the problems and issues underlying ontology
and knowledge representation:
-
http://www.jfsowa.com/pubs/signproc.htm
A proposed
architecture for intelligent systems that are designed
to handle the problems and issues discussed in this talk:
-
http://www.jfsowa.com/pubs/arch.htm
Copyright ©2002, John F. Sowa