Task-Oriented
Semantic Interpretation
John F. Sowa and Arun K. Majumdar
VivoMind LLC
Topics Covered
- Background Knowledge
- Conceptual Graphs
- Knowledge Soup
- Finding Analogies
- A Large Application
- Comparison with Other Approaches
See paper:
http://www.jfsowa.com/pubs/tosi.htm
1. Background Knowledge
Two kinds of knowledge needed for understanding language:
- Lexical knowledge: Knowledge about words, word senses,
and typical patterns of relations between words.
- Task-oriented knowledge: Knowledge about a task,
how to do it, and the environment in which it is done.
General world knowledge includes the totality of task oriented
knowledge for all the tasks that people do.
Lexical Knowledge
A sentence with an ambiguous word:
John went to the board.
Word sense determined by subsequent context:
- He kicked it to see if it was rotten.
- He wrote the homework assignment for the next week.
- He presented arguments for the proposed merger.
Task-Oriented Knowledge
A driver stops the car to ask a question:
Driver: Where is the nearest gas station?
Pedestrian: Turn right at the corner,
and go about two blocks.
D: Thanks.
A short while later, the driver comes back:
D: That gas station is closed.
P: Yes. It hasn't been open for years.
D: Why didn't you tell me?
P: You didn't ask.
The pedestrian did not have or use task-dependent knowledge about cars,
drivers, and gas stations.
Organizing Background Knowledge
Five ways of organizing knowledge for NL processing:
- Lexical semantics:
- Knowledge about words and patterns of relations.
- Broad coverage, but not deep enough
or precise enough for logical deduction.
- Axiomatized semantics:
- Formal rules or axioms intended for deduction.
- Ranging from expert systems with a few dozen rules
to the million axioms of Cyc.
- Statistical approaches:
- Empirical methods derived from large corpora.
- Many different techniques designed for different purposes.
- Knowledge soup:
- Loosely organized, dynamically changing, often contradictory
mess in the human brain.
- Simulated with combinations of the previous three methods.
- Task-oriented semantic interpretation:
- Simplification of the knowledge soup for a single task.
- Large amount of lexical knowledge, but only
axiomatized for one task.
- Implemented in a NL processor called Intellitex.
2. Conceptual Graphs
Conceptual Graph Display Format:
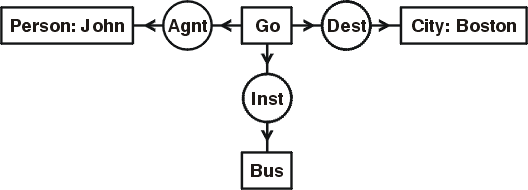
English: John is going to Boston by bus.
Conceptual Graph Interchange Format (KIF):
[Go: *x] [Person: John *y] [City: Boston *z] [Bus: *w]
(Agnt ?x ?y) (Dest ?x ?z) (Inst ?x ?z)
Knowledge Interchange Format (KIF):
(exists ((?x Go) (?y Person) (?z City) (?w Bus))
(and (Name ?y John) (Name ?z Boston)
(Agnt ?x ?y) (Dest ?x ?z) (Inst ?x ?w)))
Predicate calculus:
(∃x:Go)(∃y:Person)(∃z:City)(∃w:Bus)
(name(y,'John') ∧ name(z,'Boston') ∧
agnt(x,y) ∧ dest(x,z) ∧ inst(x,w))
CG with Indexicals
A little story:
At 10:17 UTC, there was a cat named Yojo and a mouse.
Yojo chased the mouse. Then he caught the mouse.
Then he ate the head of the mouse.

Nested contexts based on Peirce's existential graphs,
but isomorphic to Kamp's discourse representation structures.
CG with Indexicals Resolved

Nested contexts with all references resolved
Predicate calculus:
(∃s1:Situation)(pTim(s1,"10:17 UTC")
∧ dscr(s1,
(∃s1,s2,s3:Situation)(∃x:Cat)(∃y:Mouse)(name(x,"Yojo")
∧ dscr(s2, (∃u:Chase)(agnt(u,x) ∧ thme(u,y)))
∧ dscr(s3, (∃v:Catch)(agnt(v,x) ∧ thme(v,y)))
∧ dscr(s4,
(∃w:Eat)(∃z:Head)(agnt(w,x) ∧ ptnt(w,z) ∧ part(y,w)))
∧ next(s2,s3) ∧ next(s3,s4)))).
Efficient Algorithms
Graph structure supports highly efficient algorithms:
- Accessing a hierarchy of CGs in logarithmic time.
- Structural learning algorithms that use the hierarchy.
- Theorem proving with Peirce's rules of inference.
- Marker passing for path following.
- Analogy finding in (N log N) time.
3. Knowledge Soup
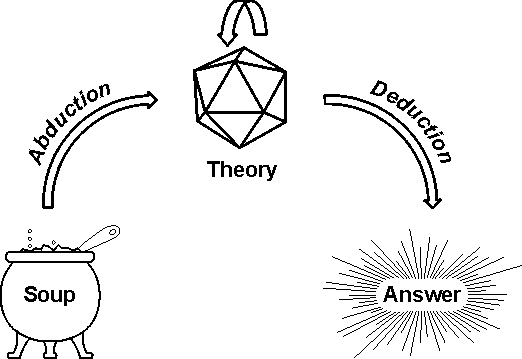
Crystallizing theories out of knowledge soup
Organizing the Knowledge Soup
- Simple lexicons are insufficient.
- A single, fixed ontology is inflexible.
- Knowledge soup is indexed by a bushy structure of graphs:
- A lexicon with multiple concept types (word senses or synsets)
for each word type.
- Multiple canonical graphs that express
typical patterns expected for each concept type.
- An open-ended lattice of theories, each of which
represents one chunk in the soup.
Pointers from Words to Theories
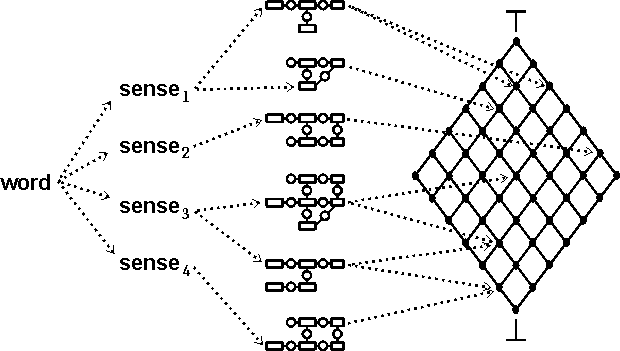
words → word senses → canonical graphs → theories
Canonical Graphs
A conceptual graph that represents a stereotypical pattern
of concept and relation types:

This canonical graph shows the typical lexical pattern
for the concept type Give.
More specialized canonical graphs can show details
for concept types at any level.
Theory Revision
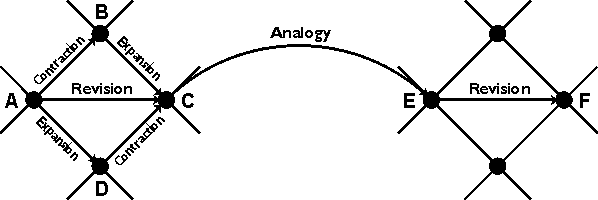
Four operators for belief or theory revision
Special Case with Just One Theory

words → word senses → canonical graphs → theory
Task-Oriented Semantic Interpretation
Canonical graphs derived from lexical resources
- Provide broad coverage of language.
- Good for disambiguating word senses.
- But not detailed enough for any specific task.
TOSI adds task-oriented canonical graphs for particular applications:
- Deeper analysis for items of interest.
- Text that maps to TOSI graphs triggers deeper reasoning.
- Text that does not match TOSI graphs is ignored.
Intellitex
- NL processor developed by VivoMind LLC.
- Lightweight parser with emphasis on semantic interpretation.
- Lexical resources derived from WordNet translated to CGs
(other resources being developed).
- Implements a version of TOSI.
- Uses analogies when needed.
- Evaluates interpretation using Bayesian statistics
with prior probabilities estimated by Dempster-Shafer theory of evidence.
4. Analogies
More primitive and more general than formal logic.
Every method of logic depends on repeated analogies:
- Deduction: unification and modus ponens.
- Induction: comparing examples and generalizing.
- Abduction: finding likely hypotheses.
Essential for nonmonotonic reasoning (belief revision).
Essential for semantic interpretation (abduction):
- Graph unification for common cases.
- General analogies for metonymy, metaphor, and exceptions.
VivoMind Analogy Engine
Three methods of analogy:
- Matching labels:
- Identical type labels.
- Subtype - supertype.
- Siblings of same supertype.
- More distant cousins.
- Matching subgraphs:
- Match isomorphic subgraphs independent of labels.
- Combine adjacent nodes to make them isomorphic.
- Matching transformations:
- Find transformations that map subgraphs to one another.
Methods #1 and #2 take (N log N) time.
Method #3 takes polynomial time (analogies of analogies).
An Example
| Analogy of Cat to Car |
|---|
| Cat | Car |
|---|
| head | hood |
| eye | headlight |
| cornea | glass plate |
| mouth | fuel cap |
| stomach | fuel tank |
| bowel | combustion chamber |
| anus | exhaust pipe |
| skeleton | chasis |
| heart | engine |
| paw | wheel |
| fur | paint |
VAE used methods #1 and #2.
All source data taken from WordNet.
Matching Labels and Subgraphs
Corresponding parts have similar functions:
- Fur and paint are outer coverings.
- Heart and engine are internal parts with a regular beat.
- Skeleton and chasis are structures for attaching parts.
- Paw and wheel support the body, and there are four of each.
Approximate matching (missing esophagus and muffler):
- Cat: mouth → stomach → bowel → anus.
- Car: fuel cap → fuel tank → combustion chamber
→ exhaust pipe.
Another pair of matching subgraphs:
- Cat: head → eyes → cornea.
- Car: hood → headlights → glass plate.
Mapping Different Representations
Method #3 for relating data structures that represent equivalent information.

- A physical structure describable in different ways:
-
English description: "A red pyramid A, a green pyramid B, and a yellow pyramid C
support a blue block D, which supports an orange pyramid E."
-
A relational database would use tables.
-
But many different options for chosing tables,
rows and columns, and labels for the columns.
Representation in a Relational DB

CG Derived from Relational DB

CG Derived from English
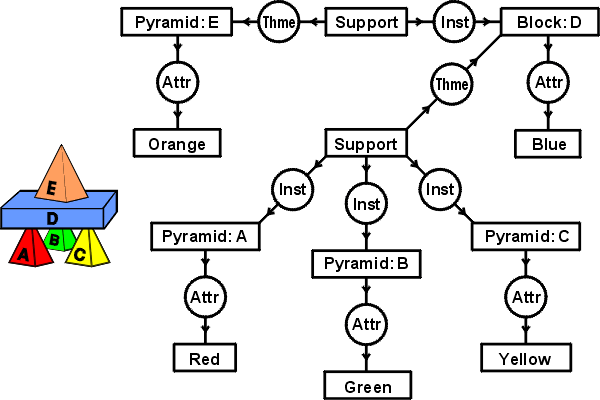
"A red pyramid A, a green pyramid B, and a yellow pyramid C
support a blue block D, which supports an orange pyramid E."
The Two CGs Look Very Different
- CG from RDB has 15 concept nodes and 8 relation nodes.
- CG from English has 12 concept nodes and 11 relation nodes.
- No label on any node in the first graph is identical to any
label on any node in the second graph.
- But there are some structural similarities.
- VAE uses method #3 to find them.
Transformations Found by VAE

Top transformation applied to 5 subgraphs.
Bottom one applied to 3 subgraphs.
One application could be due to chance, but 3 or 5 contribute
strong evidence for the mapping.
5. A Large Application
An earlier version of Intellitex was applied to three languages
— English, COBOL, and JCL:
- 1.5 million lines of COBOL.
- Several hundred JCL scripts.
- 100 megabytes of English documentation
— text files, e-mails, Lotus Notes, HTML, and transcriptions
of oral communications.
Same parser but different grammars for all three languages:
- English used canonical graphs derived from WordNet
and TOSI graphs for the application.
- COBOL and JCL did not require the WordNet graphs,
but they did use the TOSI graphs.
- Results represented in conceptual graphs independent
of the source language.
- Translated into diagrams with English text:
Glossary, data dictionary, data flow diagrams,
process architecture diagrams, system context diagrams.
Results
Job finished in 8 weeks by two programmers, Arun Majumdar
and André LeClerc.
- Four weeks for customization:
- Design and logistics.
- Additional programming for I/O formats.
- Three weeks to run Intellitex + VAE + extensions:
- 24 hours a day on a 750 MHz Pentium III.
- VAE handled matches with strong evidence.
- Matches with weak evidence were confirmed or corrected
by Majumdar and LeClerc.
- One week to produce a CD-ROM with integrated views of the results:
Glossary, data dictionary, data flow diagrams, process architecture,
system context diagrams.
Contradiction Found by VAE
From analyzing English documentation:
- Every employee is a human being.
- No human being is a computer.
From analyzing COBOL programs:
- Some employees are computers.
What is the reason for this contradiction?
Quick Patch in 1979
A COBOL programmer made a quick patch:
- Two computers were used to assist human consultants.
- But there was no provision to bill for computer time.
- Therefore, the programmer named the computers Bob and Sally,
and assigned them employee ids.
For more than 20 years:
- Bob and Sally were issued payroll checks.
- But they never cashed them.
- However, several million dollars of company funds were
inaccessible.
VAE discovered the two computer "employees".
Mismatch Found by VAE

Question: Which location determines the market?
According to the documentation: The business unit.
According to COBOL: The client HQ.
Canonical Graphs
Same task-oriented canonical graphs for interpreting the semantics
of English, COBOL, and JCL:
[Process]->(Uses)->[Data]
[Process]->(Generates)->[Data]
[Process]->(Modifies)->[Data]
With subtypes for all the kinds of processes and data,
including files and records, of COBOL and JCL.
6. Comparison with Other Approaches
Four widely used approaches in AI:
- Logic-based semantics: Precise, but slow.
- Shallow parsers: Fast, but sloppy.
- Bottom-up expert systems:
Useful, but highly specialized and not generalizable.
- Top-down ontologies:
Broader, but inflexible and not detailed enough for expert systems.
TOSI is an attempt to combine the strengths of all four,
but within a flexible, modular, generalizable framework.
Task-Oriented Semantic Interpreter
Broad-coverage syntax and semantics:
- Large lexicon based on WordNet supplemented with other resources.
- But shallow semantic coverage.
- Too much irrelevant information.
- Not detailed enough for any specific task.
TOSI supplements the lexicon with canonical graphs
for the specific task:
- Broad, but shallow parsing for everything.
- Deeper analysis for the items of interest.
- Same techniques applied to English, COBOL, and JCL
— different syntax, but same canonical graphs.
Conclusions
Conceptual graphs represent
- Shallow semantics for broad coverage.
- Deeper semantics for items of interest.
- Full power of logic for deduction, induction, and abduction.
CG tools support
- Specialization, generalization, and analogy.
- Associative search and precise deduction.
- Fast parsing and deeper analysis.
For Further Reading
A textbook on knowledge representation:
An article
that goes into further detail on these topics:
-
http://www.jfsowa.com/pubs/tosi.htm
A guided tour
of ontology, conceptual structures, and logic:
-
http://www.jfsowa.com/ontology/guided.htm
An article
about the templates used for information extraction, their use
in shallow parsing, and their relationship to conceptual graphs:
-
http://www.jfsowa.com/pubs/template.htm
A philosophical
analysis of the problems and issues underlying ontology
and knowledge representation:
-
http://www.jfsowa.com/pubs/signproc.htm
Copyright ©2002, John F. Sowa